 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Adaptive Robot Learning from Demonstration under Replication with Gaussian Process Models
Paper and Code
Oct 15, 2020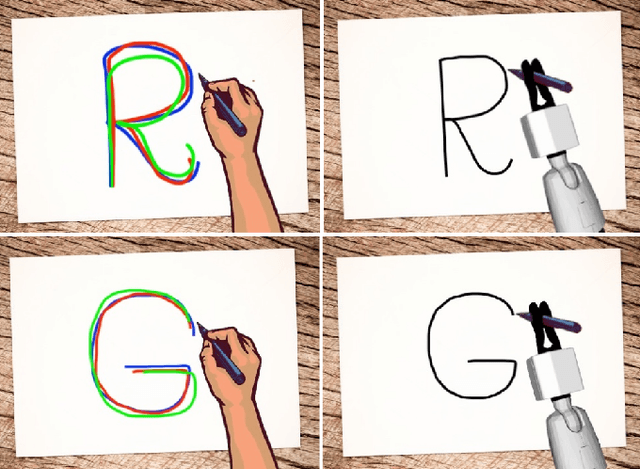
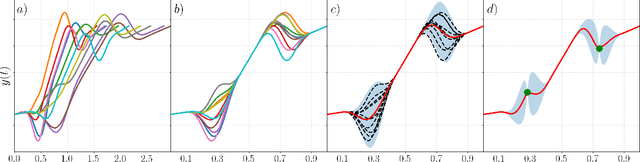
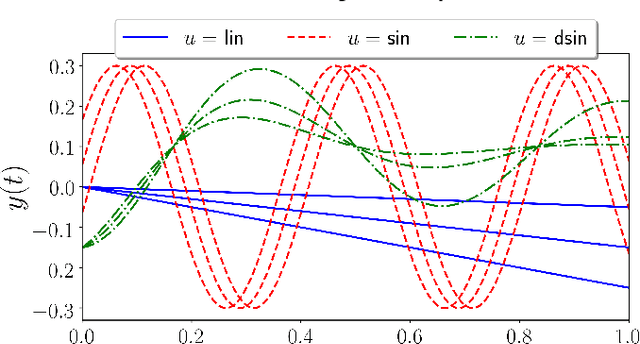
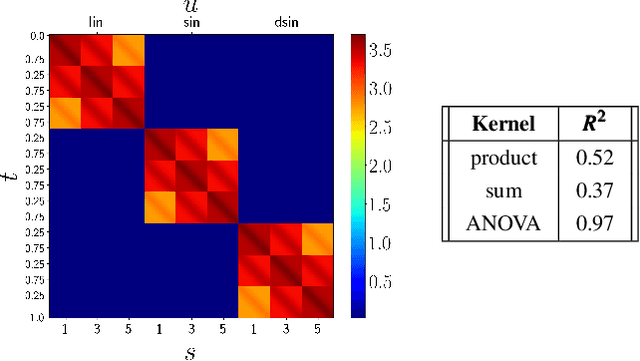
Learning from Demonstration (LfD) is a paradigm that allows robots to learn complex manipulation tasks that can not be easily scripted, but can be demonstrated by a human teacher. One of the challenges of LfD is to enable robots to acquire skills that can be adapted to different scenarios. In this paper, we propose to achieve this by exploiting the variations in the demonstrations to retrieve an adaptive and robust policy, using Gaussian Process (GP) models. Adaptability is enhanced by incorporating task parameters into the model, which encode different specifications within the same task. With our formulation, these parameters can either be real, integer, or categorical. Furthermore, we propose a GP design that exploits the structure of replications, i.e., repeated demonstrations at identical conditions within data. Our method significantly reduces the computational cost of model fitting in complex tasks, where replications are essential to obtain a robust model. We illustrate our approach through several experiments on a handwritten letter demonstration dataset.