 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeT Cell Receptor Protein Sequences and Sparse Coding: A Novel Approach to Cancer Classification
Paper and Code
Apr 25, 2023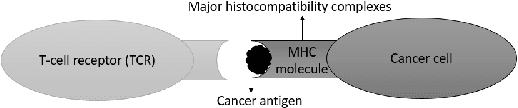
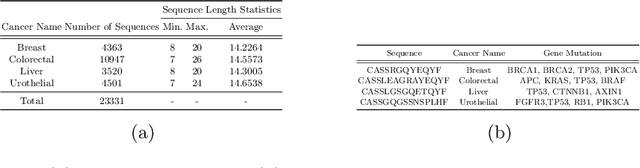
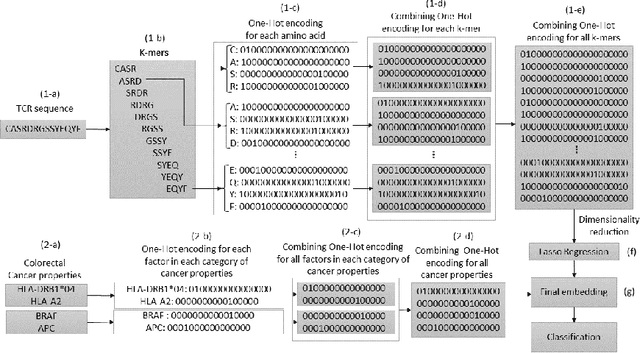
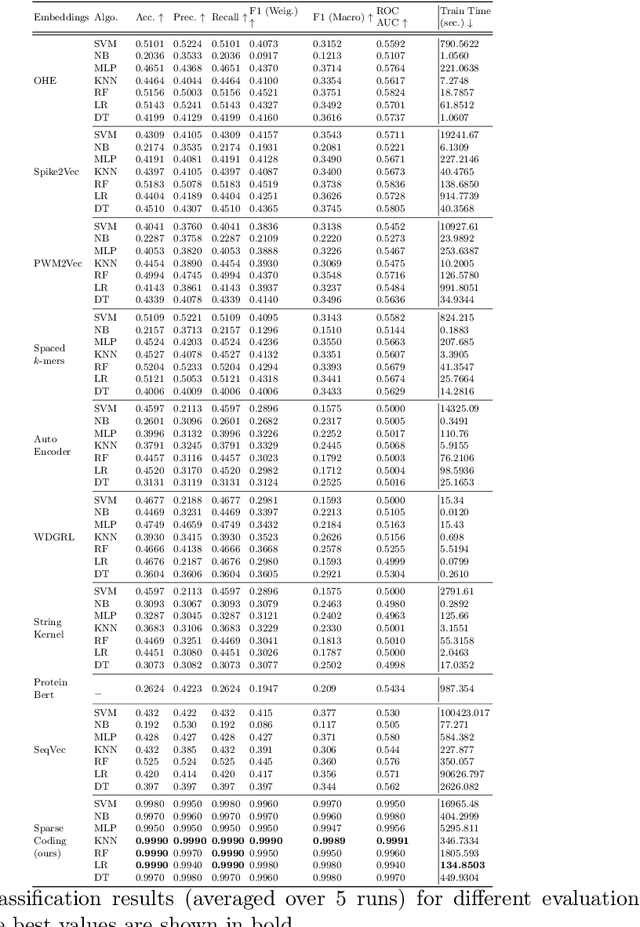
Cancer is a complex disease characterized by uncontrolled cell growth and proliferation. T cell receptors (TCRs) are essential proteins for the adaptive immune system, and their specific recognition of antigens plays a crucial role in the immune response against diseases, including cancer. The diversity and specificity of TCRs make them ideal for targeting cancer cells, and recent advancements in sequencing technologies have enabled the comprehensive profiling of TCR repertoires. This has led to the discovery of TCRs with potent anti-cancer activity and the development of TCR-based immunotherapies. In this study, we investigate the use of sparse coding for the multi-class classification of TCR protein sequences with cancer categories as target labels. Sparse coding is a popular technique in machine learning that enables the representation of data with a set of informative features and can capture complex relationships between amino acids and identify subtle patterns in the sequence that might be missed by low-dimensional methods. We first compute the k-mers from the TCR sequences and then apply sparse coding to capture the essential features of the data. To improve the predictive performance of the final embeddings, we integrate domain knowledge regarding different types of cancer properties. We then train different machine learning (linear and non-linear) classifiers on the embeddings of TCR sequences for the purpose of supervised analysis. Our proposed embedding method on a benchmark dataset of TCR sequences significantly outperforms the baselines in terms of predictive performance, achieving an accuracy of 99.8\%. Our study highlights the potential of sparse coding for the analysis of TCR protein sequences in cancer research and other related fields.