 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured Multimodal Attentions for TextVQA
Paper and Code

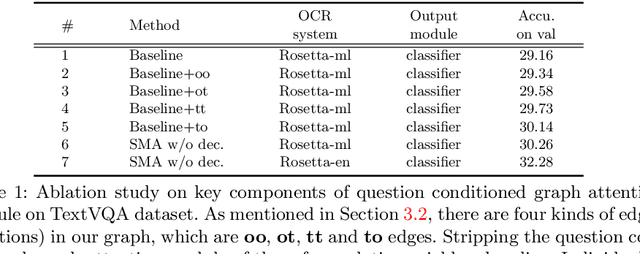


Text based Visual Question Answering (TextVQA) is a recently raised challenge that requires a machine to read text in images and answer natural language questions by jointly reasoning over the question, Optical Character Recognition (OCR) tokens and visual content. Most of the state-of-the-art (SoTA) VQA methods fail to answer these questions because of i) poor text reading ability; ii) lacking of text-visual reasoning capacity; and iii) adopting a discriminative answering mechanism instead of a generative one which is hard to cover both OCR tokens and general text tokens in the final answer. In this paper, we propose a structured multimodal attention (SMA) neural network to solve the above issues. Our SMA first uses a structural graph representation to encode the object-object, object-text and text-text relationships appearing in the image, and then design a multimodal graph attention network to reason over it. Finally, the outputs from the above module are processed by a global-local attentional answering module to produce an answer that covers tokens from both OCR and general text iteratively. Our proposed model outperforms the SoTA models on TextVQA dataset and all three tasks of ST-VQA dataset. To provide an upper bound for our method and a fair testing base for further works, we also provide human-annotated ground-truth OCR annotations for the TextVQA dataset, which were not given in the original release.