 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured Knowledge Distillation for Semantic Segmentation
Paper and Code
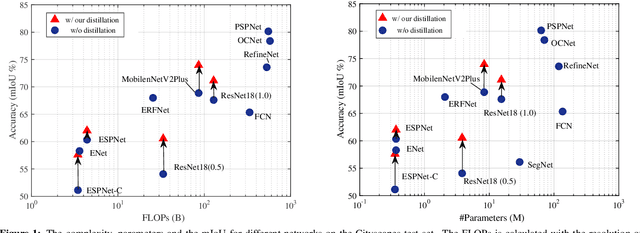
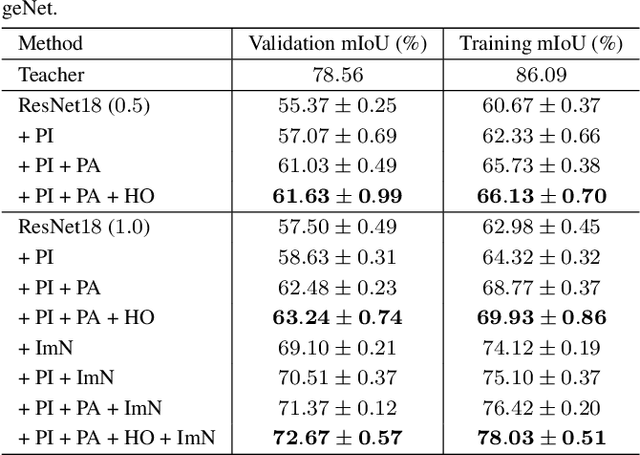

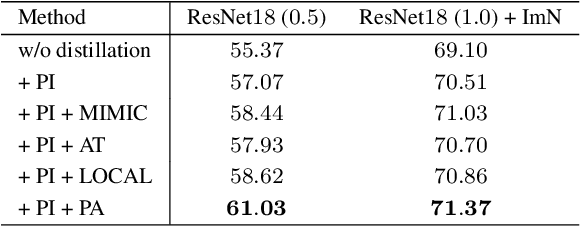
In this paper, we investigate the knowledge distillation strategy for training small semantic segmentation networks by making use of large networks. We start from the straightforward scheme, pixel-wise distillation, which applies the distillation scheme adopted for image classification and performs knowledge distillation for each pixel separately. We further propose to distill the structured knowledge from large networks to small networks, which is motivated by that semantic segmentation is a structured prediction problem. We study two structured distillation schemes: (i) pair-wise distillation that distills the pairwise similarities, and (ii) holistic distillation that uses GAN to distill holistic knowledge. The effectiveness of our knowledge distillation approaches is demonstrated by extensive experiments on three scene parsing datasets: Cityscapes, Camvid and ADE20K.