 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured Inverse-Free Natural Gradient: Memory-Efficient & Numerically-Stable KFAC for Large Neural Nets
Paper and Code


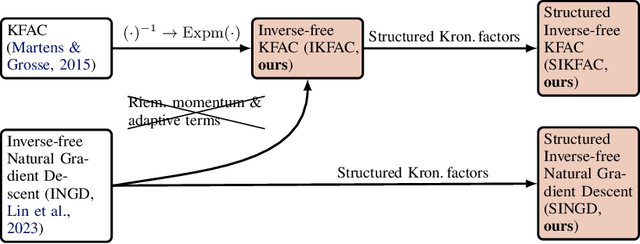

Second-order methods for deep learning -- such as KFAC -- can be useful for neural net training. However, they are often memory-inefficient and numerically unstable for low-precision training since their preconditioning Kronecker factors are dense, and require high-precision matrix inversion or decomposition. Consequently, such methods are not widely used for training large neural networks such as transformer-based models. We address these two issues by (i) formulating an inverse-free update of KFAC and (ii) imposing structures in each of the Kronecker factors, resulting in a method we term structured inverse-free natural gradient descent (SINGD). On large modern neural networks, we show that, in contrast to KFAC, SINGD is memory efficient and numerically robust, and often outperforms AdamW even in half precision. Hence, our work closes a gap between first-order and second-order methods in modern low precision training for large neural nets.