 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructural Bias for Aspect Sentiment Triplet Extraction
Paper and Code
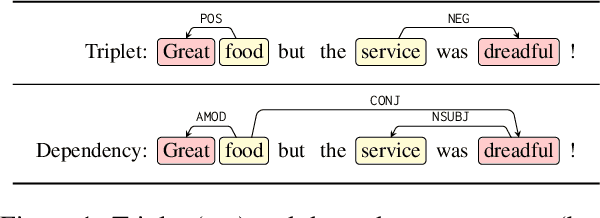
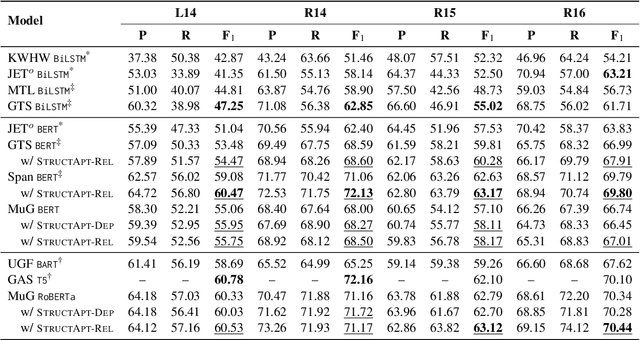
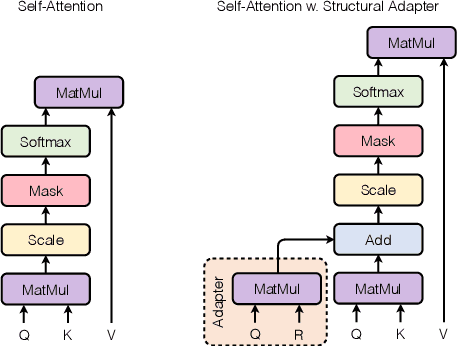
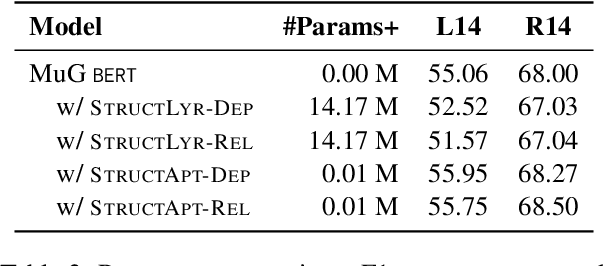
Structural bias has recently been exploited for aspect sentiment triplet extraction (ASTE) and led to improved performance. On the other hand, it is recognized that explicitly incorporating structural bias would have a negative impact on efficiency, whereas pretrained language models (PLMs) can already capture implicit structures. Thus, a natural question arises: Is structural bias still a necessity in the context of PLMs? To answer the question, we propose to address the efficiency issues by using an adapter to integrate structural bias in the PLM and using a cheap-to-compute relative position structure in place of the syntactic dependency structure. Benchmarking evaluation is conducted on the SemEval datasets. The results show that our proposed structural adapter is beneficial to PLMs and achieves state-of-the-art performance over a range of strong baselines, yet with a light parameter demand and low latency. Meanwhile, we give rise to the concern that the current evaluation default with data of small scale is under-confident. Consequently, we release a large-scale dataset for ASTE. The results on the new dataset hint that the structural adapter is confidently effective and efficient to a large scale. Overall, we draw the conclusion that structural bias shall still be a necessity even with PLMs.