 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeST++: Make Self-training Work Better for Semi-supervised Semantic Segmentation
Paper and Code
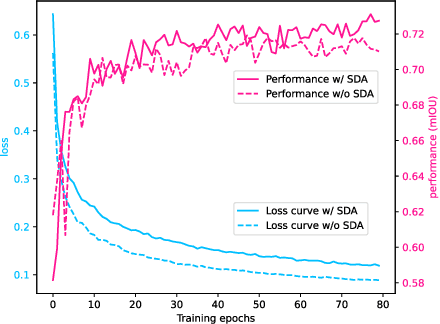

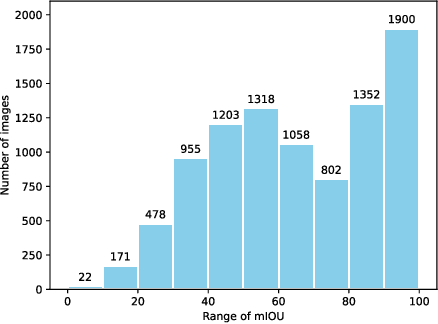

In this paper, we investigate if we could make the self-training -- a simple but popular framework -- work better for semi-supervised segmentation. Since the core issue in semi-supervised setting lies in effective and efficient utilization of unlabeled data, we notice that increasing the diversity and hardness of unlabeled data is crucial to performance improvement. Being aware of this fact, we propose to adopt the most plain self-training scheme coupled with appropriate strong data augmentations on unlabeled data (namely ST) for this task, which surprisingly outperforms previous methods under various settings without any bells and whistles. Moreover, to alleviate the negative impact of the wrongly pseudo labeled images, we further propose an advanced self-training framework (namely ST++), that performs selective re-training via selecting and prioritizing the more reliable unlabeled images. As a result, the proposed ST++ boosts the performance of semi-supervised model significantly and surpasses existing methods by a large margin on the Pascal VOC 2012 and Cityscapes benchmark. Overall, we hope this straightforward and simple framework will serve as a strong baseline or competitor for future works. Code is available at https://github.com/LiheYoung/ST-PlusPlus.