 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoft-Labeled Contrastive Pre-training for Function-level Code Representation
Paper and Code



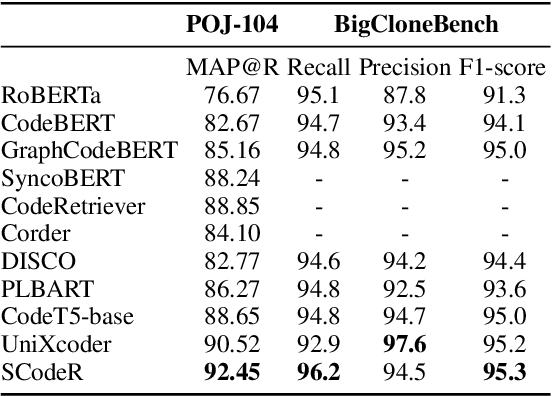
Code contrastive pre-training has recently achieved significant progress on code-related tasks. In this paper, we present \textbf{SCodeR}, a \textbf{S}oft-labeled contrastive pre-training framework with two positive sample construction methods to learn functional-level \textbf{Code} \textbf{R}epresentation. Considering the relevance between codes in a large-scale code corpus, the soft-labeled contrastive pre-training can obtain fine-grained soft-labels through an iterative adversarial manner and use them to learn better code representation. The positive sample construction is another key for contrastive pre-training. Previous works use transformation-based methods like variable renaming to generate semantically equal positive codes. However, they usually result in the generated code with a highly similar surface form, and thus mislead the model to focus on superficial code structure instead of code semantics. To encourage SCodeR to capture semantic information from the code, we utilize code comments and abstract syntax sub-trees of the code to build positive samples. We conduct experiments on four code-related tasks over seven datasets. Extensive experimental results show that SCodeR achieves new state-of-the-art performance on all of them, which illustrates the effectiveness of the proposed pre-training method.