 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLAP: Simultaneous Localization and Planning Under Uncertainty for Physical Mobile Robots via Dynamic Replanning in Belief Space: Extended version
Paper and Code
May 13, 2018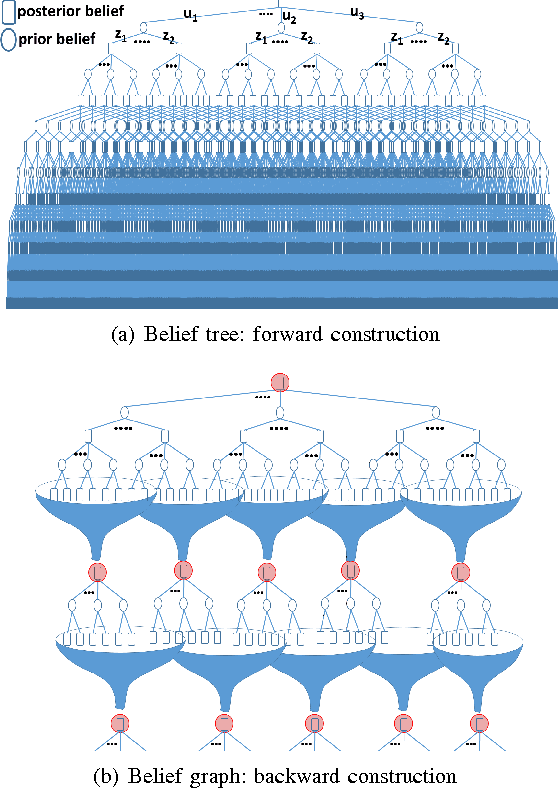

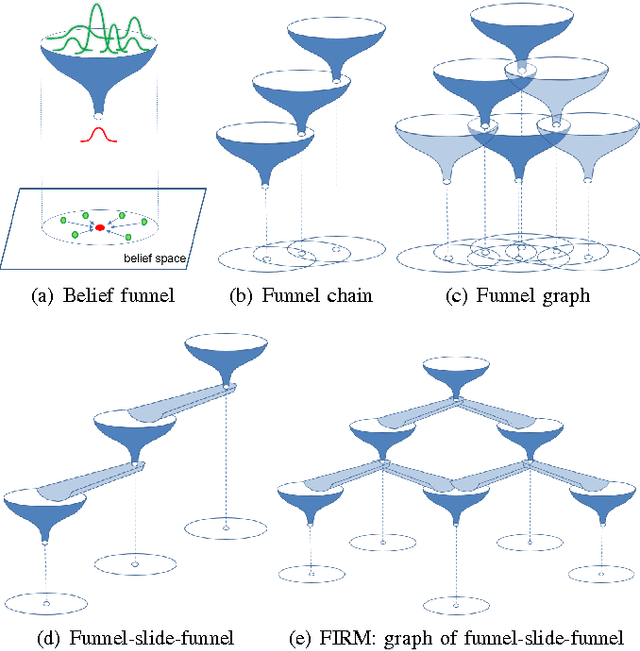

Simultaneous localization and Planning (SLAP) is a crucial ability for an autonomous robot operating under uncertainty. In its most general form, SLAP induces a continuous POMDP (partially-observable Markov decision process), which needs to be repeatedly solved online. This paper addresses this problem and proposes a dynamic replanning scheme in belief space. The underlying POMDP, which is continuous in state, action, and observation space, is approximated offline via sampling-based methods, but operates in a replanning loop online to admit local improvements to the coarse offline policy. This construct enables the proposed method to combat changing environments and large localization errors, even when the change alters the homotopy class of the optimal trajectory. It further outperforms the state-of-the-art FIRM (Feedback-based Information RoadMap) method by eliminating unnecessary stabilization steps. Applying belief space planning to physical systems brings with it a plethora of challenges. A key focus of this paper is to implement the proposed planner on a physical robot and show the SLAP solution performance under uncertainty, in changing environments and in the presence of large disturbances, such as a kidnapped robot situation.