 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle-Stream Multi-Level Alignment for Vision-Language Pretraining
Paper and Code
Mar 30, 2022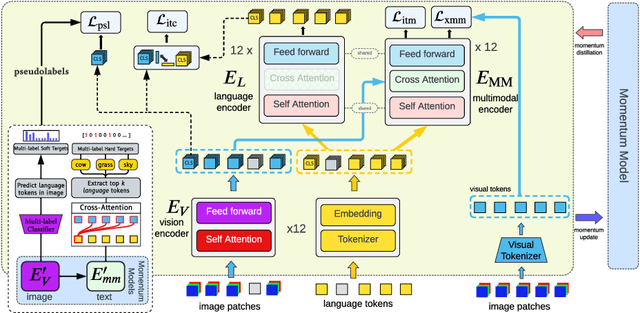
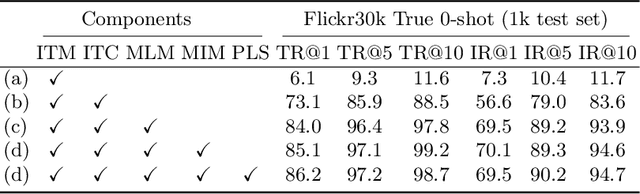
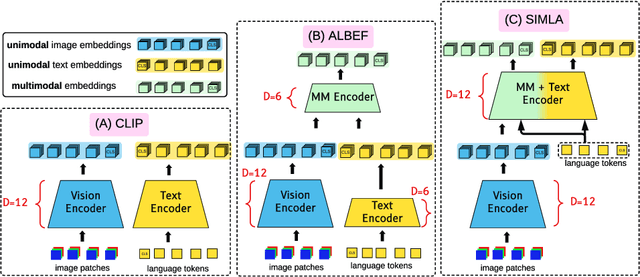
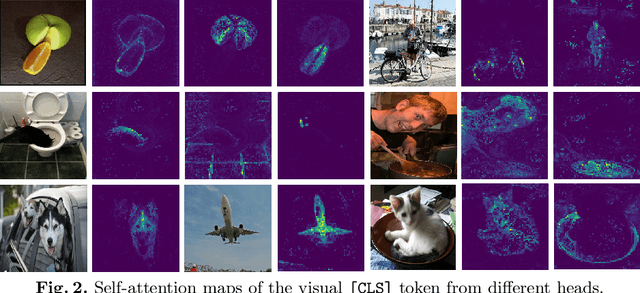
Recent progress in large-scale vision-language pre-training has shown the importance of aligning the visual and text modalities for downstream vision-language tasks. Many methods use a dual-stream architecture that fuses visual tokens and language tokens after representation learning, which aligns only at a global level and cannot extract finer-scale semantics. In contrast, we propose a single stream model that aligns the modalities at multiple levels: i) instance level, ii) fine-grained patch level, iii) conceptual semantic level. We achieve this using two novel tasks: symmetric cross-modality reconstruction and a pseudo-labeled key word prediction. In the former part, we mask the input tokens from one of the modalities and use the cross-modal information to reconstruct the masked token, thus improving fine-grained alignment between the two modalities. In the latter part, we parse the caption to select a few key words and feed it together with the momentum encoder pseudo signal to self-supervise the visual encoder, enforcing it to learn rich semantic concepts that are essential for grounding a textual token to an image region. We demonstrate top performance on a set of Vision-Language downstream tasks such as zero-shot/fine-tuned image/text retrieval, referring expression, and VQA. We also demonstrate how the proposed models can align the modalities at multiple levels.