 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimulSLT: End-to-End Simultaneous Sign Language Translation
Paper and Code
Dec 08, 2021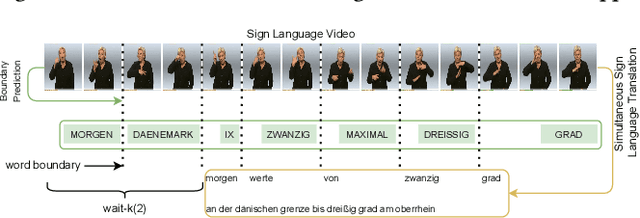
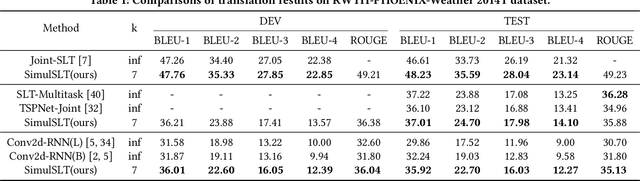
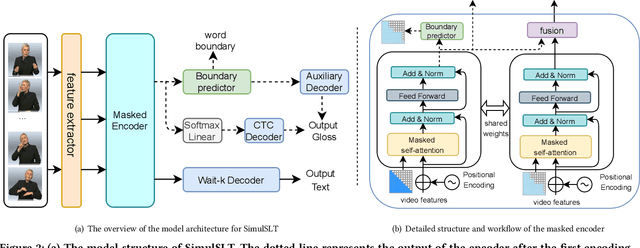

Sign language translation as a kind of technology with profound social significance has attracted growing researchers' interest in recent years. However, the existing sign language translation methods need to read all the videos before starting the translation, which leads to a high inference latency and also limits their application in real-life scenarios. To solve this problem, we propose SimulSLT, the first end-to-end simultaneous sign language translation model, which can translate sign language videos into target text concurrently. SimulSLT is composed of a text decoder, a boundary predictor, and a masked encoder. We 1) use the wait-k strategy for simultaneous translation. 2) design a novel boundary predictor based on the integrate-and-fire module to output the gloss boundary, which is used to model the correspondence between the sign language video and the gloss. 3) propose an innovative re-encode method to help the model obtain more abundant contextual information, which allows the existing video features to interact fully. The experimental results conducted on the RWTH-PHOENIX-Weather 2014T dataset show that SimulSLT achieves BLEU scores that exceed the latest end-to-end non-simultaneous sign language translation model while maintaining low latency, which proves the effectiveness of our method.