 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimple and Robust Loss Design for Multi-Label Learning with Missing Labels
Paper and Code
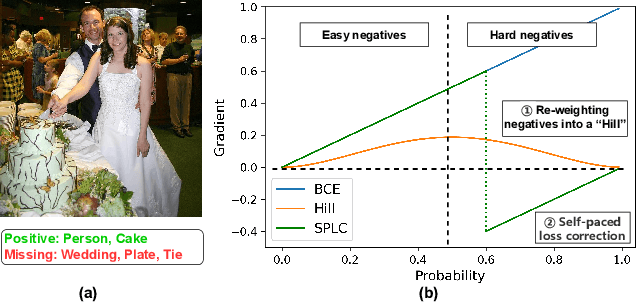
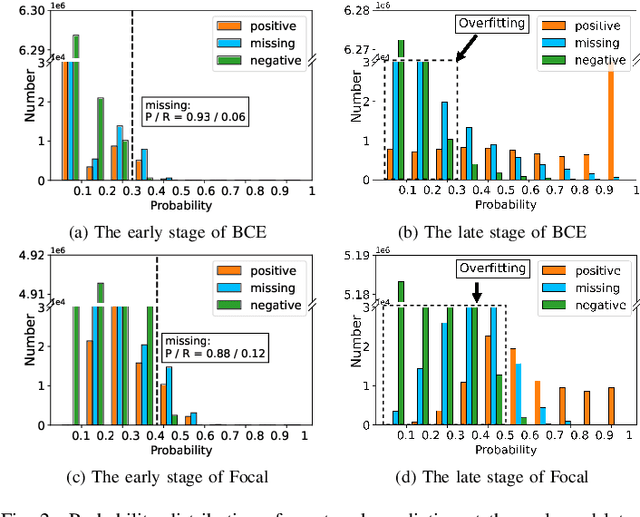
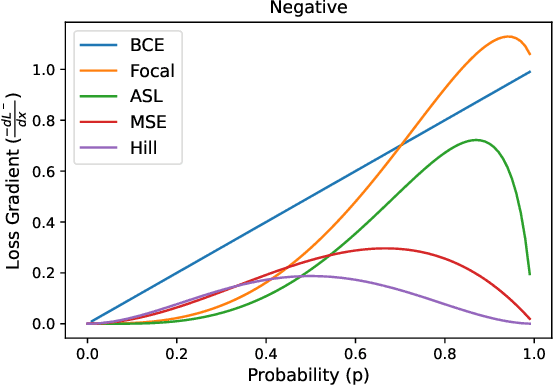
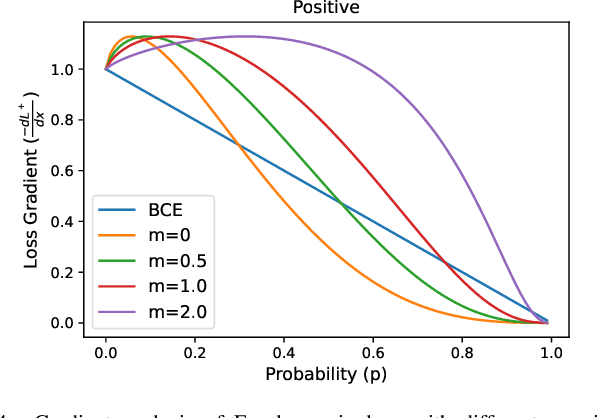
Multi-label learning in the presence of missing labels (MLML) is a challenging problem. Existing methods mainly focus on the design of network structures or training schemes, which increase the complexity of implementation. This work seeks to fulfill the potential of loss function in MLML without increasing the procedure and complexity. Toward this end, we propose two simple yet effective methods via robust loss design based on an observation that a model can identify missing labels during training with a high precision. The first is a novel robust loss for negatives, namely the Hill loss, which re-weights negatives in the shape of a hill to alleviate the effect of false negatives. The second is a self-paced loss correction (SPLC) method, which uses a loss derived from the maximum likelihood criterion under an approximate distribution of missing labels. Comprehensive experiments on a vast range of multi-label image classification datasets demonstrate that our methods can remarkably boost the performance of MLML and achieve new state-of-the-art loss functions in MLML.