 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimCVD: Simple Contrastive Voxel-Wise Representation Distillation for Semi-Supervised Medical Image Segmentation
Paper and Code
Aug 16, 2021


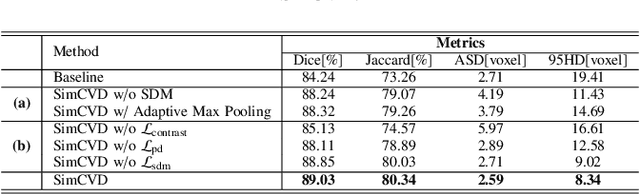
Automated segmentation in medical image analysis is a challenging task that requires a large amount of manually labeled data. However, most existing learning-based approaches usually suffer from limited manually annotated medical data, which poses a major practical problem for accurate and robust medical image segmentation. In addition, most existing semi-supervised approaches are usually not robust compared with the supervised counterparts, and also lack explicit modeling of geometric structure and semantic information, both of which limit the segmentation accuracy. In this work, we present SimCVD, a simple contrastive distillation framework that significantly advances state-of-the-art voxel-wise representation learning. We first describe an unsupervised training strategy, which takes two views of an input volume and predicts their signed distance maps of object boundaries in a contrastive objective, with only two independent dropout as mask. This simple approach works surprisingly well, performing on the same level as previous fully supervised methods with much less labeled data. We hypothesize that dropout can be viewed as a minimal form of data augmentation and makes the network robust to representation collapse. Then, we propose to perform structural distillation by distilling pair-wise similarities. We evaluate SimCVD on two popular datasets: the Left Atrial Segmentation Challenge (LA) and the NIH pancreas CT dataset. The results on the LA dataset demonstrate that, in two types of labeled ratios (i.e., 20% and 10%), SimCVD achieves an average Dice score of 90.85% and 89.03% respectively, a 0.91% and 2.22% improvement compared to previous best results. Our method can be trained in an end-to-end fashion, showing the promise of utilizing SimCVD as a general framework for downstream tasks, such as medical image synthesis and registration.