 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemEval-2019 Task 6: Identifying and Categorizing Offensive Language in Social Media (OffensEval)
Paper and Code

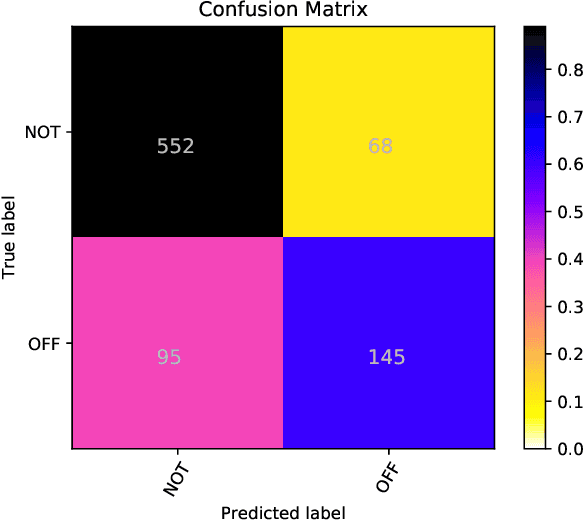
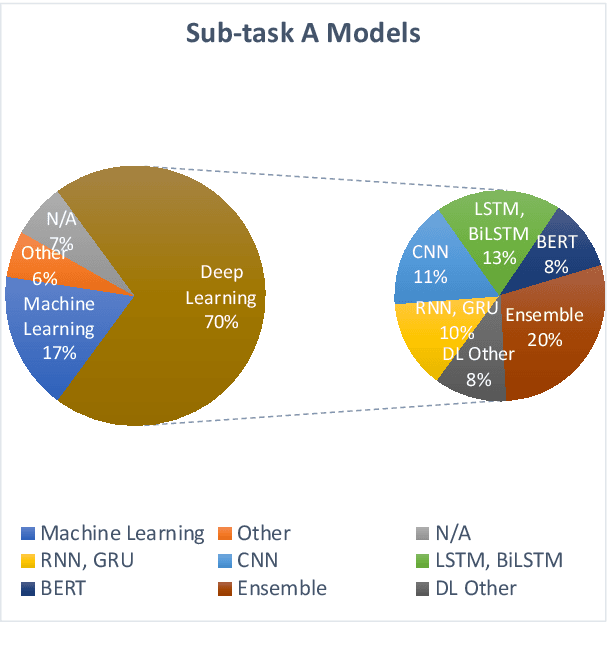
This paper presents the results and main findings of the Identifying and Categorizing Offensive Language in Social Media (OffensEval) shared task organized with SemEval-2019. SemEval-2019 Task 6 provided participants with the Offensive Language Identification Dataset (OLID), an annotated dataset containing over 14,000 English tweets. The competition was divided into three sub-tasks. In sub-task A systems were trained to discriminate between offensive and non-offensive tweets, in sub-task B systems were trained to identify the type of offensive content in the post, and finally, in sub-task C systems were trained to identify the target of offensive posts. OffensEval attracted a large number of participants and it was one of the most popular tasks in SemEval-2019. In total, nearly 800 teams signed up to participate in the task and 115 of them submitted results which are presented and analyzed in this report.