 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic-preserved Communication System for Highly Efficient Speech Transmission
Paper and Code
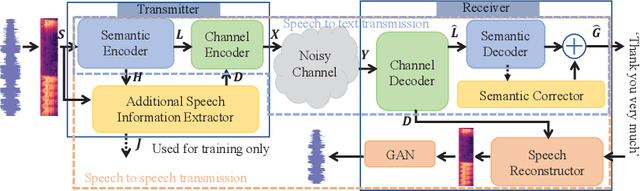
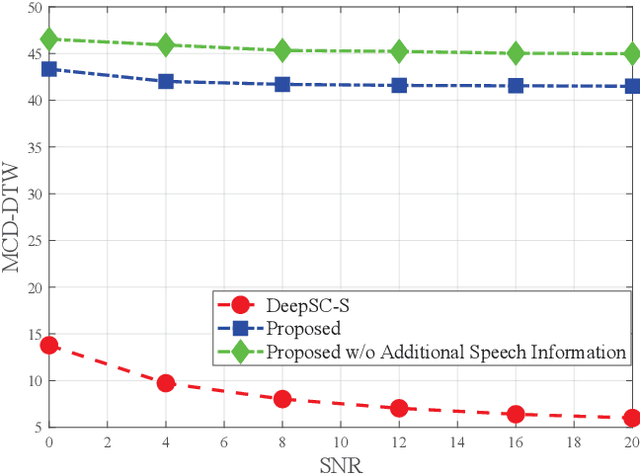
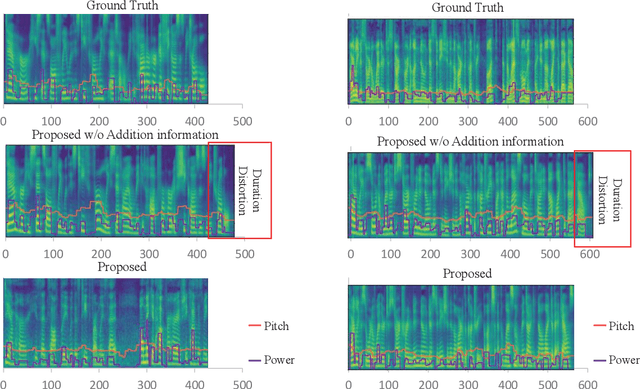
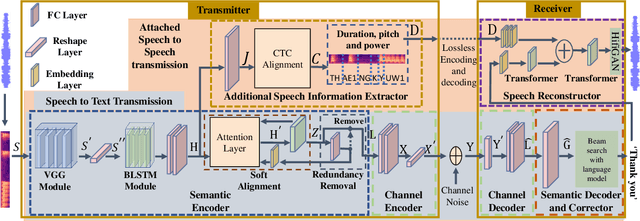
Deep learning (DL) based semantic communication methods have been explored for the efficient transmission of images, text, and speech in recent years. In contrast to traditional wireless communication methods that focus on the transmission of abstract symbols, semantic communication approaches attempt to achieve better transmission efficiency by only sending the semantic-related information of the source data. In this paper, we consider semantic-oriented speech transmission which transmits only the semantic-relevant information over the channel for the speech recognition task, and a compact additional set of semantic-irrelevant information for the speech reconstruction task. We propose a novel end-to-end DL-based transceiver which extracts and encodes the semantic information from the input speech spectrums at the transmitter and outputs the corresponding transcriptions from the decoded semantic information at the receiver. For the speech to speech transmission, we further include a CTC alignment module that extracts a small number of additional semantic-irrelevant but speech-related information for the better reconstruction of the original speech signals at the receiver. The simulation results confirm that our proposed method outperforms current methods in terms of the accuracy of the predicted text for the speech to text transmission and the quality of the recovered speech signals for the speech to speech transmission, and significantly improves transmission efficiency. More specifically, the proposed method only sends 16% of the amount of the transmitted symbols required by the existing methods while achieving about 10% reduction in WER for the speech to text transmission. For the speech to speech transmission, it results in an even more remarkable improvement in terms of transmission efficiency with only 0.2% of the amount of the transmitted symbols required by the existing method.