 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Conditioned Dynamic Modulation for Temporal Sentence Grounding in Videos
Paper and Code

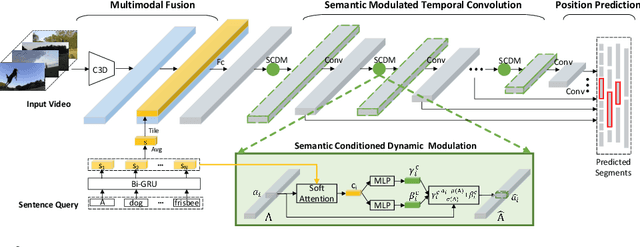


Temporal sentence grounding in videos aims to detect and localize one target video segment, which semantically corresponds to a given sentence. Existing methods mainly tackle this task via matching and aligning semantics between a sentence and candidate video segments, while neglect the fact that the sentence information plays an important role in temporally correlating and composing the described contents in videos. In this paper, we propose a novel semantic conditioned dynamic modulation (SCDM) mechanism, which relies on the sentence semantics to modulate the temporal convolution operations for better correlating and composing the sentence related video contents over time. More importantly, the proposed SCDM performs dynamically with respect to the diverse video contents so as to establish a more precise matching relationship between sentence and video, thereby improving the temporal grounding accuracy. Extensive experiments on three public datasets demonstrate that our proposed model outperforms the state-of-the-arts with clear margins, illustrating the ability of SCDM to better associate and localize relevant video contents for temporal sentence grounding. Our code for this paper is available at https://github.com/yytzsy/SCDM .