 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-training of Machine Learning Models for Liver Histopathology: Generalization under Clinical Shifts
Paper and Code
Nov 14, 2022

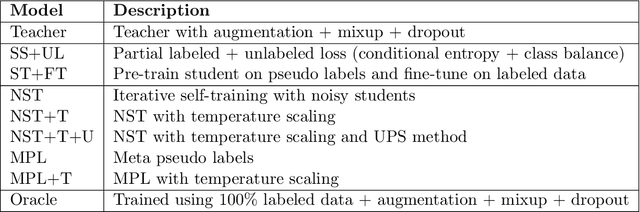

Histopathology images are gigapixel-sized and include features and information at different resolutions. Collecting annotations in histopathology requires highly specialized pathologists, making it expensive and time-consuming. Self-training can alleviate annotation constraints by learning from both labeled and unlabeled data, reducing the amount of annotations required from pathologists. We study the design of teacher-student self-training systems for Non-alcoholic Steatohepatitis (NASH) using clinical histopathology datasets with limited annotations. We evaluate the models on in-distribution and out-of-distribution test data under clinical data shifts. We demonstrate that through self-training, the best student model statistically outperforms the teacher with a $3\%$ absolute difference on the macro F1 score. The best student model also approaches the performance of a fully supervised model trained with twice as many annotations.