 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Smoothing Graph Neural Networks
Paper and Code
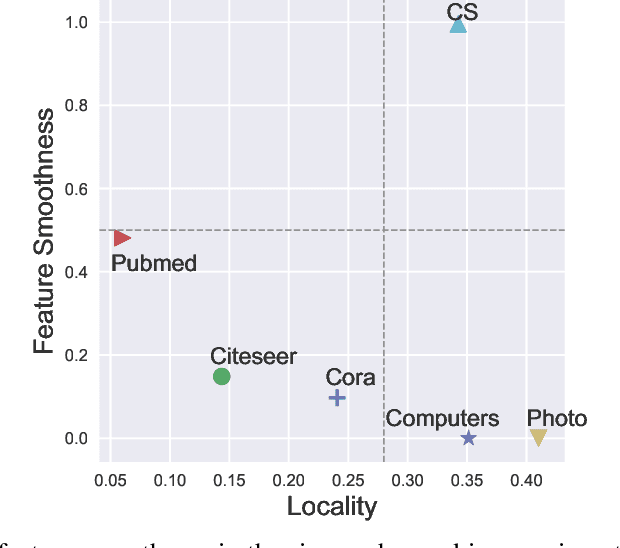
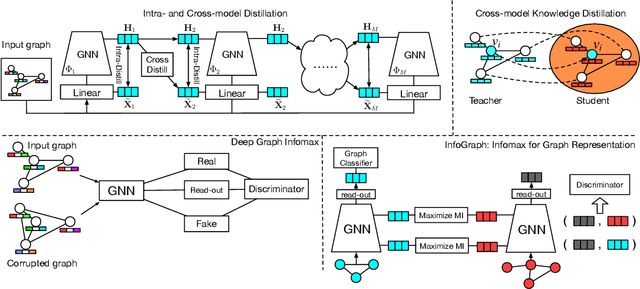
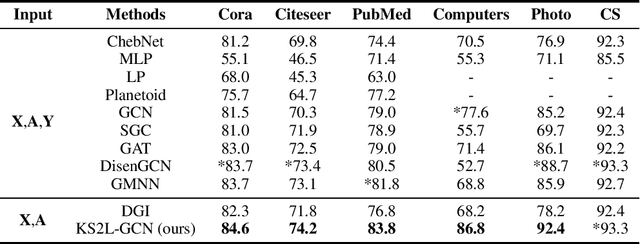
This paper studies learning node representations with GNNs for unsupervised scenarios. We make a theoretical understanding and empirical demonstration about the non-steady performance of GNNs over different graph datasets, when the supervision signals are not appropriately defined. The performance of GNNs depends on both the node feature smoothness and the graph locality. To smooth the discrepancy of node proximity measured by graph topology and node feature, we proposed KS2L - a novel graph \underline{K}nowledge distillation regularized \underline{S}elf-\underline{S}upervised \underline{L}earning framework, with two complementary regularization modules, for intra-and cross-model graph knowledge distillation. We demonstrate the competitive performance of KS2L on a variety of benchmarks. Even with a single GCN layer, KS2L has consistently competitive or even better performance on various benchmark datasets.