 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Learning for Visual Summary Identification in Scientific Publications
Paper and Code
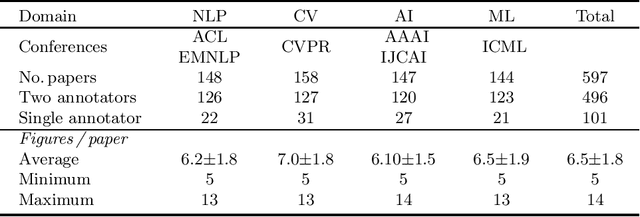
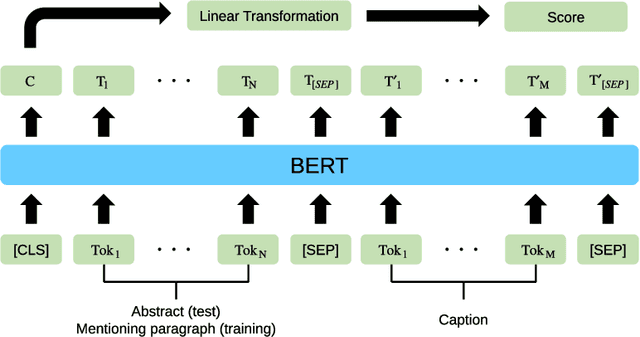
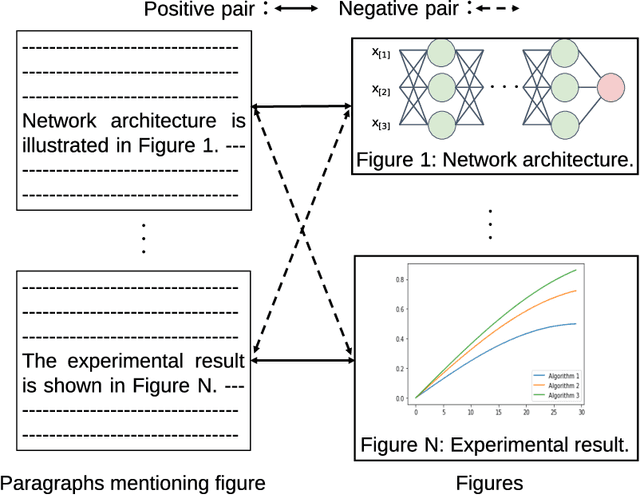

Providing visual summaries of scientific publications can increase information access for readers and thereby help deal with the exponential growth in the number of scientific publications. Nonetheless, efforts in providing visual publication summaries have been few and far apart, primarily focusing on the biomedical domain. This is primarily because of the limited availability of annotated gold standards, which hampers the application of robust and high-performing supervised learning techniques. To address these problems we create a new benchmark dataset for selecting figures to serve as visual summaries of publications based on their abstracts, covering several domains in computer science. Moreover, we develop a self-supervised learning approach, based on heuristic matching of inline references to figures with figure captions. Experiments in both biomedical and computer science domains show that our model is able to outperform the state of the art despite being self-supervised and therefore not relying on any annotated training data.