 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegregated Temporal Assembly Recurrent Networks for Weakly Supervised Multiple Action Detection
Paper and Code
Nov 19, 2018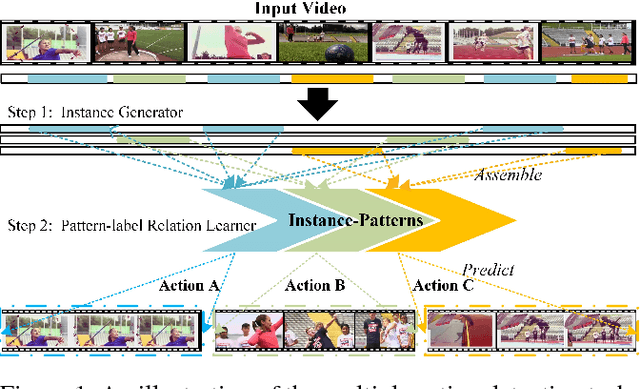



This paper proposes a segregated temporal assembly recurrent (STAR) network for weakly-supervised multiple action detection. The model learns from untrimmed videos with only supervision of video-level labels and makes prediction of intervals of multiple actions. Specifically, we first assemble video clips according to class labels by an attention mechanism that learns class-variable attention weights and thus helps the noise relieving from background or other actions. Secondly, we build temporal relationship between actions by feeding the assembled features into an enhanced recurrent neural network. Finally, we transform the output of recurrent neural network into the corresponding action distribution. In order to generate more precise temporal proposals, we design a score term called segregated temporal gradient-weighted class activation mapping (ST-GradCAM) fused with attention weights. Experiments on THUMOS'14 and ActivityNet1.3 datasets show that our approach outperforms the state-of-the-art weakly-supervised method, and performs at par with the fully-supervised counterparts.