 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegment Everything Everywhere All at Once
Paper and Code

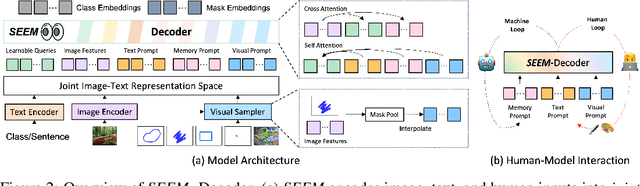


Despite the growing demand for interactive AI systems, there have been few comprehensive studies on human-AI interaction in visual understanding e.g. segmentation. Inspired by the development of prompt-based universal interfaces for LLMs, this paper presents SEEM, a promptable, interactive model for Segmenting Everything Everywhere all at once in an image. SEEM has four desiderata: i) Versatility: by introducing a versatile prompting engine for different types of prompts, including points, boxes, scribbles, masks, texts, and referred regions of another image; ii) Compositionality: by learning a joint visual-semantic space for visual and textual prompts to compose queries on the fly for inference as shown in Fig 1; iii)Interactivity: by incorporating learnable memory prompts to retain dialog history information via mask-guided cross-attention; and iv) Semantic-awareness: by using a text encoder to encode text queries and mask labels for open-vocabulary segmentation.