 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEED-Story: Multimodal Long Story Generation with Large Language Model
Paper and Code


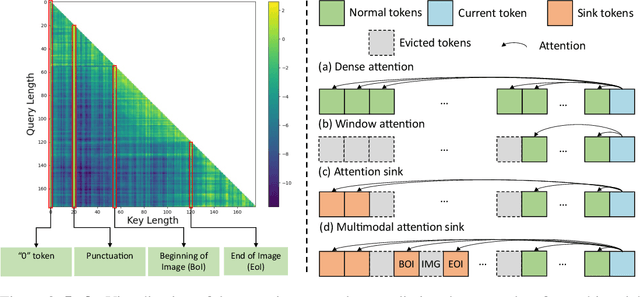

With the remarkable advancements in image generation and open-form text generation, the creation of interleaved image-text content has become an increasingly intriguing field. Multimodal story generation, characterized by producing narrative texts and vivid images in an interleaved manner, has emerged as a valuable and practical task with broad applications. However, this task poses significant challenges, as it necessitates the comprehension of the complex interplay between texts and images, and the ability to generate long sequences of coherent, contextually relevant texts and visuals. In this work, we propose SEED-Story, a novel method that leverages a Multimodal Large Language Model (MLLM) to generate extended multimodal stories. Our model, built upon the powerful comprehension capability of MLLM, predicts text tokens as well as visual tokens, which are subsequently processed with an adapted visual de-tokenizer to produce images with consistent characters and styles. We further propose multimodal attention sink mechanism to enable the generation of stories with up to 25 sequences (only 10 for training) in a highly efficient autoregressive manner. Additionally, we present a large-scale and high-resolution dataset named StoryStream for training our model and quantitatively evaluating the task of multimodal story generation in various aspects.