 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScene Graph for Embodied Exploration in Cluttered Scenario
Paper and Code
Jul 16, 2022
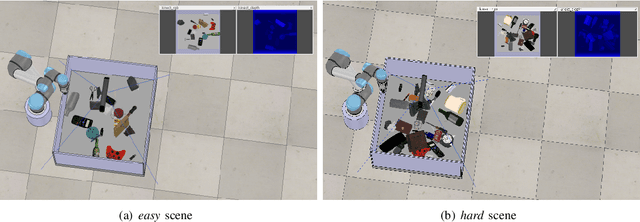
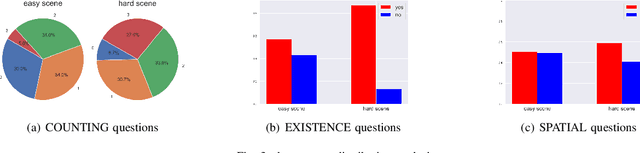
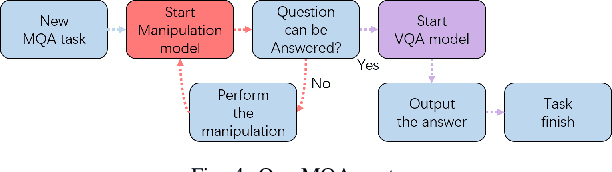
The ability to handle objects in cluttered environment has been long anticipated by robotic community. However, most of works merely focus on manipulation instead of rendering hidden semantic information in cluttered objects. In this work, we introduce the scene graph for embodied exploration in cluttered scenarios to solve this problem. To validate our method in cluttered scenario, we adopt the Manipulation Question Answering (MQA) tasks as our test benchmark, which requires an embodied robot to have the active exploration ability and semantic understanding ability of vision and language.As a general solution framework to the task, we propose an imitation learning method to generate manipulations for exploration. Meanwhile, a VQA model based on dynamic scene graph is adopted to comprehend a series of RGB frames from wrist camera of manipulator along with every step of manipulation is conducted to answer questions in our framework.The experiments on of MQA dataset with different interaction requirements demonstrate that our proposed framework is effective for MQA task a representative of tasks in cluttered scenario.