 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling up Kernels in 3D CNNs
Paper and Code

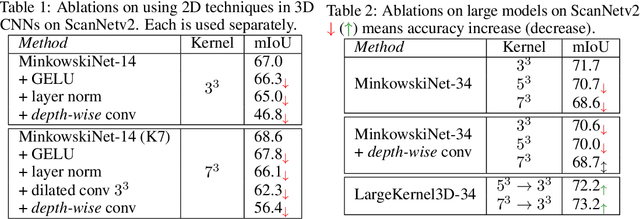


Recent advances in 2D CNNs and vision transformers (ViTs) reveal that large kernels are essential for enough receptive fields and high performance. Inspired by this literature, we examine the feasibility and challenges of 3D large-kernel designs. We demonstrate that applying large convolutional kernels in 3D CNNs has more difficulties in both performance and efficiency. Existing techniques that work well in 2D CNNs are ineffective in 3D networks, including the popular depth-wise convolutions. To overcome these obstacles, we present the spatial-wise group convolution and its large-kernel module (SW-LK block). It avoids the optimization and efficiency issues of naive 3D large kernels. Our large-kernel 3D CNN network, i.e., LargeKernel3D, yields non-trivial improvements on various 3D tasks, including semantic segmentation and object detection. Notably, it achieves 73.9% mIoU on the ScanNetv2 semantic segmentation and 72.8% NDS nuScenes object detection benchmarks, ranking 1st on the nuScenes LIDAR leaderboard. It is further boosted to 74.2% NDS with a simple multi-modal fusion. LargeKernel3D attains comparable or superior results than its CNN and transformer counterparts. For the first time, we show that large kernels are feasible and essential for 3D networks.