 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSATA: Sparsity-Aware Training Accelerator for Spiking Neural Networks
Paper and Code
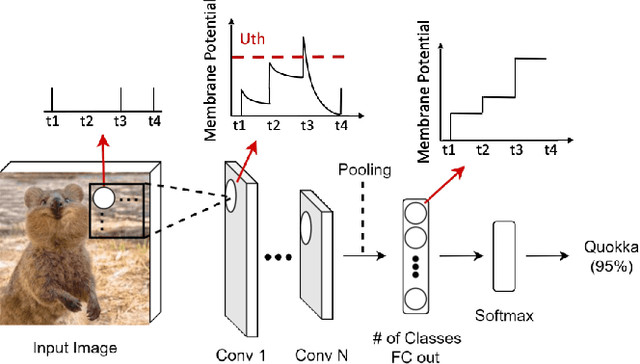


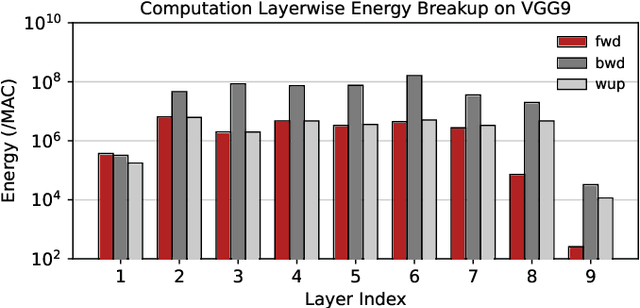
Spiking Neural Networks (SNNs) have gained huge attention as a potential energy-efficient alternative to conventional Artificial Neural Networks (ANNs) due to their inherent high-sparsity activation. Recently, SNNs with backpropagation through time (BPTT) have achieved a higher accuracy result on image recognition tasks compared to other SNN training algorithms. Despite the success on the algorithm perspective, prior works neglect the evaluation of the hardware energy overheads of BPTT, due to the lack of a hardware evaluation platform for SNN training algorithm design. Moreover, although SNNs have been long seen as an energy-efficient counterpart of ANNs, a quantitative comparison between the training cost of SNNs and ANNs is missing. To address the above-mentioned issues, in this work, we introduce SATA (Sparsity-Aware Training Accelerator), a BPTT-based training accelerator for SNNs. The proposed SATA provides a simple and re-configurable accelerator architecture for the general-purpose hardware evaluation platform, which makes it easier to analyze the training energy for SNN training algorithms. Based on SATA, we show quantitative analyses on the energy efficiency of SNN training and make a comparison between the training cost of SNNs and ANNs. The results show that SNNs consume $1.27\times$ more total energy with considering sparsity (spikes, gradient of firing function, and gradient of membrane potential) when compared to ANNs. We find that such high training energy cost is from time-repetitive convolution operations and data movements during backpropagation. Moreover, to guide the future SNN training algorithm design, we provide several observations on energy efficiency with respect to different SNN-specific training parameters.