Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRUC+CMU: System Report for Dense Captioning Events in Videos
Paper and Code
Jun 22, 2018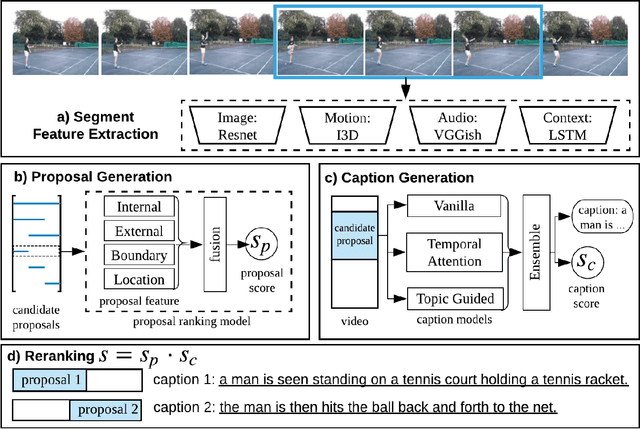
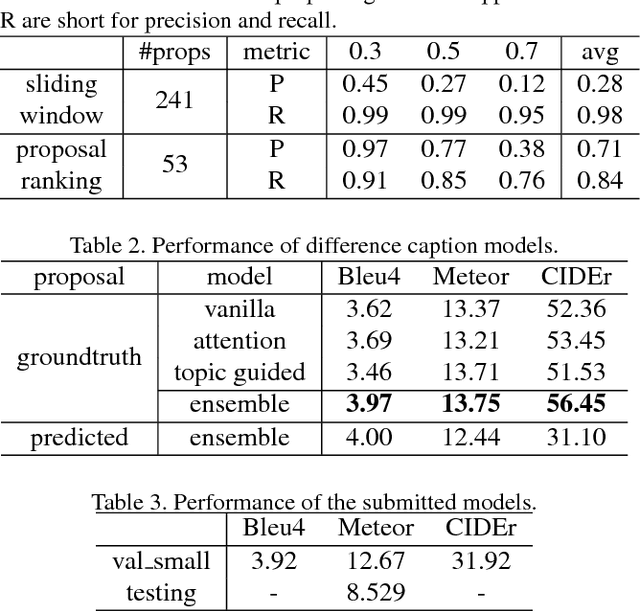
This notebook paper presents our system in the ActivityNet Dense Captioning in Video task (task 3). Temporal proposal generation and caption generation are both important to the dense captioning task. Therefore, we propose a proposal ranking model to employ a set of effective feature representations for proposal generation, and ensemble a series of caption models enhanced with context information to generate captions robustly on predicted proposals. Our approach achieves the state-of-the-art performance on the dense video captioning task with 8.529 METEOR score on the challenge testing set.
* Winner in ActivityNet 2018 Dense Video Captioning challenge
View paper on