 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobot Fine-Tuning Made Easy: Pre-Training Rewards and Policies for Autonomous Real-World Reinforcement Learning
Paper and Code
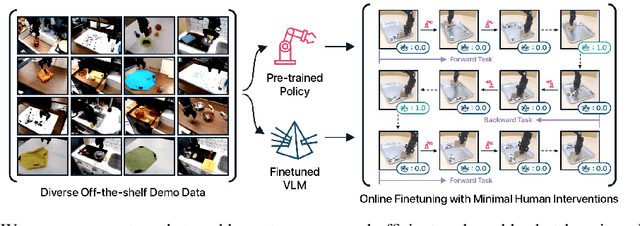


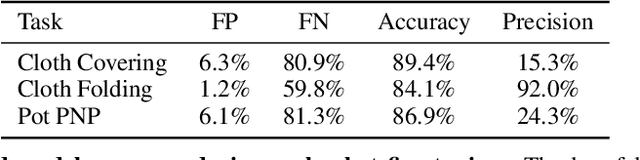
The pre-train and fine-tune paradigm in machine learning has had dramatic success in a wide range of domains because the use of existing data or pre-trained models on the internet enables quick and easy learning of new tasks. We aim to enable this paradigm in robotic reinforcement learning, allowing a robot to learn a new task with little human effort by leveraging data and models from the Internet. However, reinforcement learning often requires significant human effort in the form of manual reward specification or environment resets, even if the policy is pre-trained. We introduce RoboFuME, a reset-free fine-tuning system that pre-trains a multi-task manipulation policy from diverse datasets of prior experiences and self-improves online to learn a target task with minimal human intervention. Our insights are to utilize calibrated offline reinforcement learning techniques to ensure efficient online fine-tuning of a pre-trained policy in the presence of distribution shifts and leverage pre-trained vision language models (VLMs) to build a robust reward classifier for autonomously providing reward signals during the online fine-tuning process. In a diverse set of five real robot manipulation tasks, we show that our method can incorporate data from an existing robot dataset collected at a different institution and improve on a target task within as little as 3 hours of autonomous real-world experience. We also demonstrate in simulation experiments that our method outperforms prior works that use different RL algorithms or different approaches for predicting rewards. Project website: https://robofume.github.io