 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting the Transferability of Supervised Pretraining: an MLP Perspective
Paper and Code

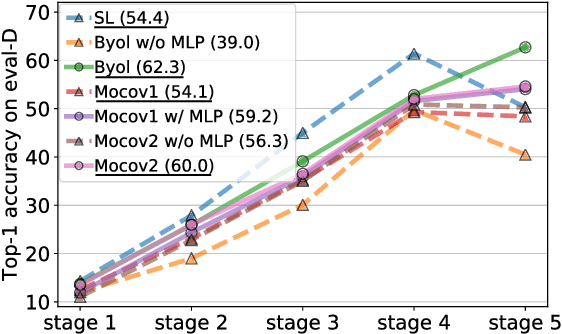

The pretrain-finetune paradigm is a classical pipeline in visual learning. Recent progress on unsupervised pretraining methods shows superior transfer performance to their supervised counterparts. This paper revisits this phenomenon and sheds new light on understanding the transferability gap between unsupervised and supervised pretraining from a multilayer perceptron (MLP) perspective. While previous works focus on the effectiveness of MLP on unsupervised image classification where pretraining and evaluation are conducted on the same dataset, we reveal that the MLP projector is also the key factor to better transferability of unsupervised pretraining methods than supervised pretraining methods. Based on this observation, we attempt to close the transferability gap between supervised and unsupervised pretraining by adding an MLP projector before the classifier in supervised pretraining. Our analysis indicates that the MLP projector can help retain intra-class variation of visual features, decrease the feature distribution distance between pretraining and evaluation datasets, and reduce feature redundancy. Extensive experiments on public benchmarks demonstrate that the added MLP projector significantly boosts the transferability of supervised pretraining, \eg \textbf{+7.2\%} top-1 accuracy on the concept generalization task, \textbf{+5.8\%} top-1 accuracy for linear evaluation on 12-domain classification tasks, and \textbf{+0.8\%} AP on COCO object detection task, making supervised pretraining comparable or even better than unsupervised pretraining. Codes will be released upon acceptance.