 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Sparse Gaussian Processes: Bayesian Approaches to Inducing-Variable Approximations
Paper and Code

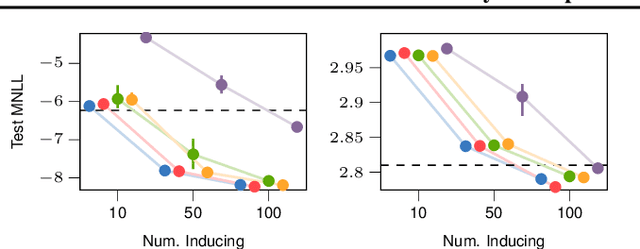
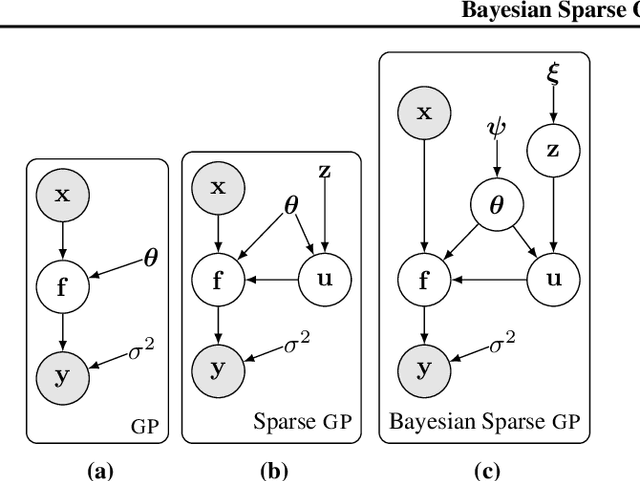
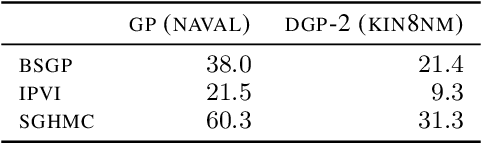
Variational inference techniques based on inducing variables provide an elegant framework for scalable posterior estimation in Gaussian process (GP) models. Most previous works treat the locations of the inducing variables, i.e. the inducing inputs, as variational hyperparameters, and these are then optimized together with GP covariance hyper-parameters. While some approaches point to the benefits of a Bayesian treatment of GP hyper-parameters, this has been largely overlooked for the inducing inputs. In this work, we show that treating both inducing locations and GP hyper-parameters in a Bayesian way, by inferring their full posterior, further significantly improves performance. Based on stochastic gradient Hamiltonian Monte Carlo, we develop a fully Bayesian approach to scalable GP and deep GP models, and demonstrate its competitive performance through an extensive experimental campaign across several regression and classification problems.