 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Knowledge Graph Propagation for Zero-Shot Learning
Paper and Code
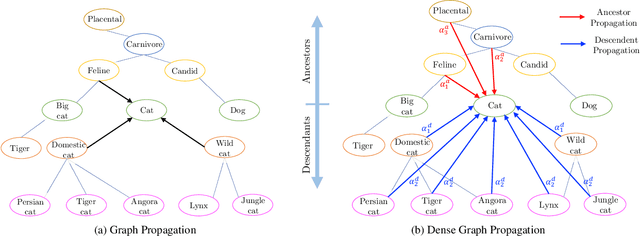

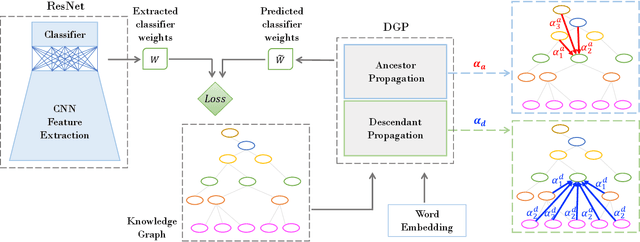

The potential of graph convolutional neural networks for the task of zero-shot learning has been demonstrated recently. These models are highly sample efficient as related concepts in the graph structure share statistical strength allowing generalization to new classes when faced with a lack of data. However, knowledge from distant nodes can get diluted when propagating through intermediate nodes, because current approaches to zero-shot learning use graph propagation schemes that perform Laplacian smoothing at each layer. We show that extensive smoothing does not help the task of regressing classifier weights in zero-shot learning. In order to still incorporate information from distant nodes and utilize the graph structure, we propose an Attentive Dense Graph Propagation Module (ADGPM). ADGPM allows us to exploit the hierarchical graph structure of the knowledge graph through additional connections. These connections are added based on a node's relationship to its ancestors and descendants and an attention scheme is further used to weigh their contribution depending on the distance to the node. Finally, we illustrate that finetuning of the feature representation after training the ADGPM leads to considerable improvements. Our method achieves competitive results, outperforming previous zero-shot learning approaches.