 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReservoir-size dependent learning in analogue neural networks
Paper and Code
Jul 23, 2019
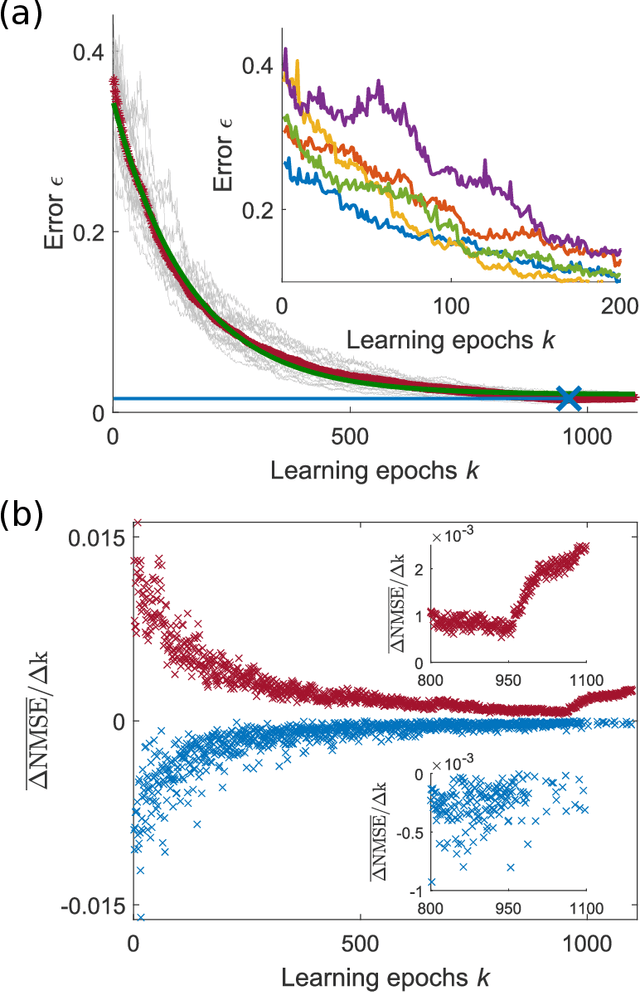
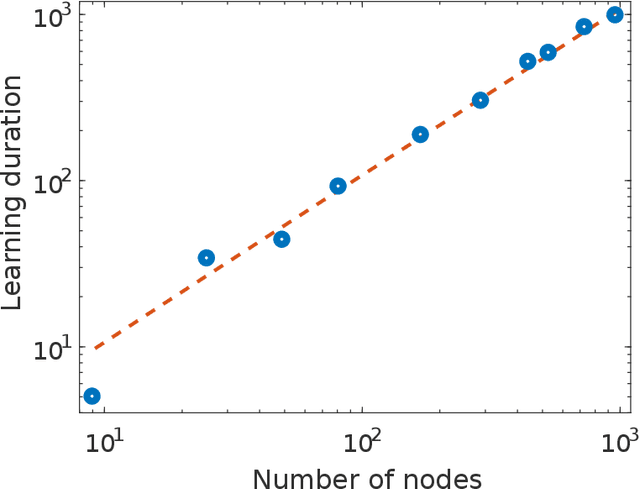
The implementation of artificial neural networks in hardware substrates is a major interdisciplinary enterprise. Well suited candidates for physical implementations must combine nonlinear neurons with dedicated and efficient hardware solutions for both connectivity and training. Reservoir computing addresses the problems related with the network connectivity and training in an elegant and efficient way. However, important questions regarding impact of reservoir size and learning routines on the convergence-speed during learning remain unaddressed. Here, we study in detail the learning process of a recently demonstrated photonic neural network based on a reservoir. We use a greedy algorithm to train our neural network for the task of chaotic signals prediction and analyze the learning-error landscape. Our results unveil fundamental properties of the system's optimization hyperspace. Particularly, we determine the convergence speed of learning as a function of reservoir size and find exceptional, close to linear scaling. This linear dependence, together with our parallel diffractive coupling, represent optimal scaling conditions for our photonic neural network scheme.