 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReMix: A General and Efficient Framework for Multiple Instance Learning based Whole Slide Image Classification
Paper and Code
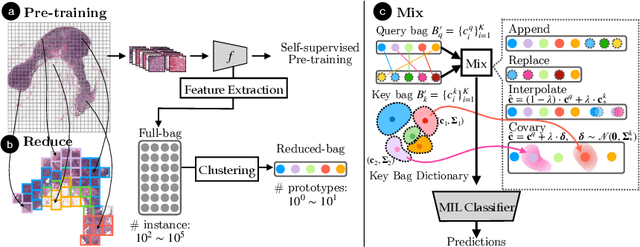
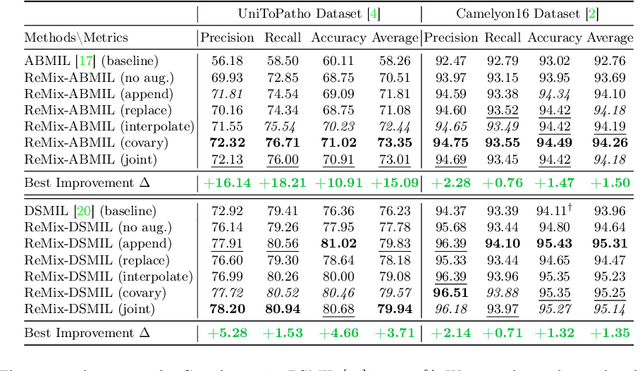


Whole slide image (WSI) classification often relies on deep weakly supervised multiple instance learning (MIL) methods to handle gigapixel resolution images and slide-level labels. Yet the decent performance of deep learning comes from harnessing massive datasets and diverse samples, urging the need for efficient training pipelines for scaling to large datasets and data augmentation techniques for diversifying samples. However, current MIL-based WSI classification pipelines are memory-expensive and computation-inefficient since they usually assemble tens of thousands of patches as bags for computation. On the other hand, despite their popularity in other tasks, data augmentations are unexplored for WSI MIL frameworks. To address them, we propose ReMix, a general and efficient framework for MIL based WSI classification. It comprises two steps: reduce and mix. First, it reduces the number of instances in WSI bags by substituting instances with instance prototypes, i.e., patch cluster centroids. Then, we propose a ``Mix-the-bag'' augmentation that contains four online, stochastic and flexible latent space augmentations. It brings diverse and reliable class-identity-preserving semantic changes in the latent space while enforcing semantic-perturbation invariance. We evaluate ReMix on two public datasets with two state-of-the-art MIL methods. In our experiments, consistent improvements in precision, accuracy, and recall have been achieved but with orders of magnitude reduced training time and memory consumption, demonstrating ReMix's effectiveness and efficiency. Code is available.