 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReliability Does Matter: An End-to-End Weakly Supervised Semantic Segmentation Approach
Paper and Code
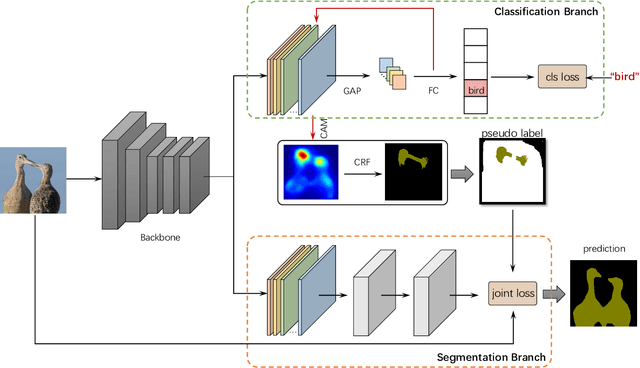



Weakly supervised semantic segmentation is a challenging task as it only takes image-level information as supervision for training but produces pixel-level predictions for testing. To address such a challenging task, most recent state-of-the-art approaches propose to adopt two-step solutions, \emph{i.e. } 1) learn to generate pseudo pixel-level masks, and 2) engage FCNs to train the semantic segmentation networks with the pseudo masks. However, the two-step solutions usually employ many bells and whistles in producing high-quality pseudo masks, making this kind of methods complicated and inelegant. In this work, we harness the image-level labels to produce reliable pixel-level annotations and design a fully end-to-end network to learn to predict segmentation maps. Concretely, we firstly leverage an image classification branch to generate class activation maps for the annotated categories, which are further pruned into confident yet tiny object/background regions. Such reliable regions are then directly served as ground-truth labels for the parallel segmentation branch, where a newly designed dense energy loss function is adopted for optimization. Despite its apparent simplicity, our one-step solution achieves competitive mIoU scores (\emph{val}: 62.6, \emph{test}: 62.9) on Pascal VOC compared with those two-step state-of-the-arts. By extending our one-step method to two-step, we get a new state-of-the-art performance on the Pascal VOC (\emph{val}: 66.3, \emph{test}: 66.5).