 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREGRAD: A Large-Scale Relational Grasp Dataset for Safe and Object-Specific Robotic Grasping in Clutter
Paper and Code
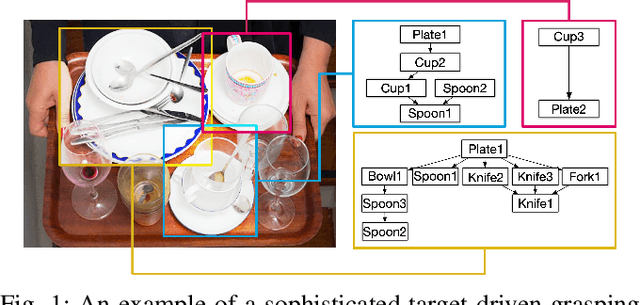
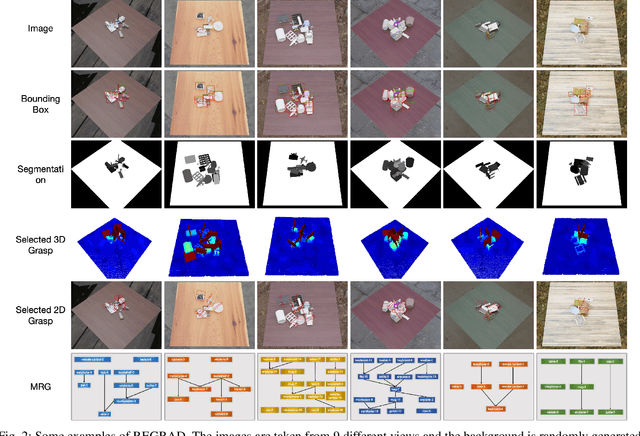
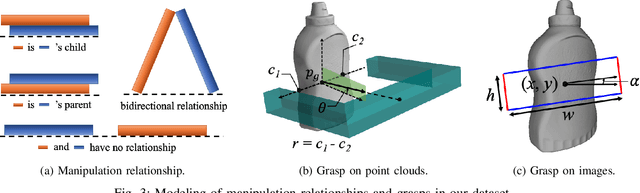
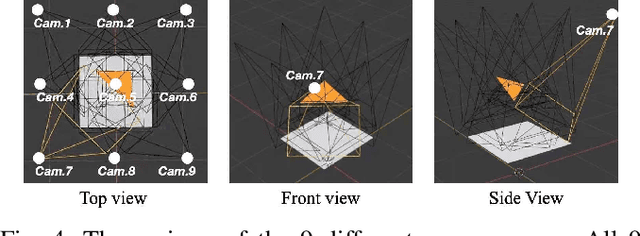
Despite the impressive progress achieved in robust grasp detection, robots are not skilled in sophisticated grasping tasks (e.g. search and grasp a specific object in clutter). Such tasks involve not only grasping, but comprehensive perception of the visual world (e.g. the relationship between objects). Recently, the advanced deep learning techniques provide a promising way for understanding the high-level visual concepts. It encourages robotic researchers to explore solutions for such hard and complicated fields. However, deep learning usually means data-hungry. The lack of data severely limits the performance of deep-learning-based algorithms. In this paper, we present a new dataset named \regrad to sustain the modeling of relationships among objects and grasps. We collect the annotations of object poses, segmentations, grasps, and relationships in each image for comprehensive perception of grasping. Our dataset is collected in both forms of 2D images and 3D point clouds. Moreover, since all the data are generated automatically, users are free to import their own object models for the generation of as many data as they want. We have released our dataset and codes. A video that demonstrates the process of data generation is also available.