 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReADS: A Rectified Attentional Double Supervised Network for Scene Text Recognition
Paper and Code
Apr 07, 2020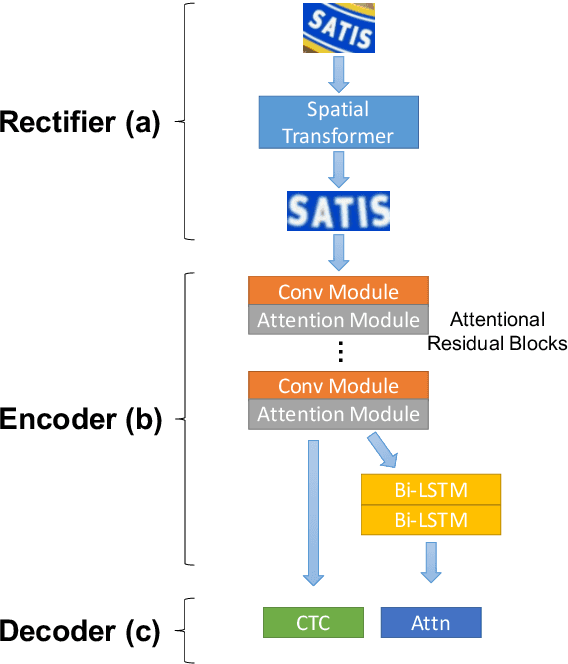
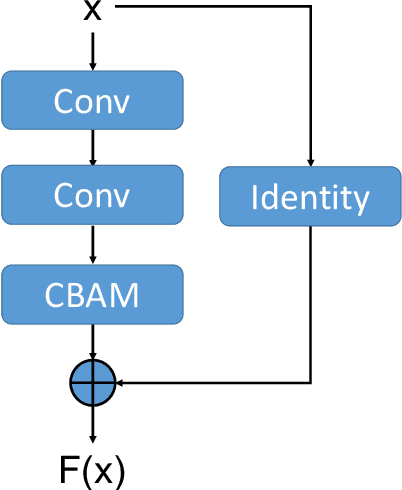

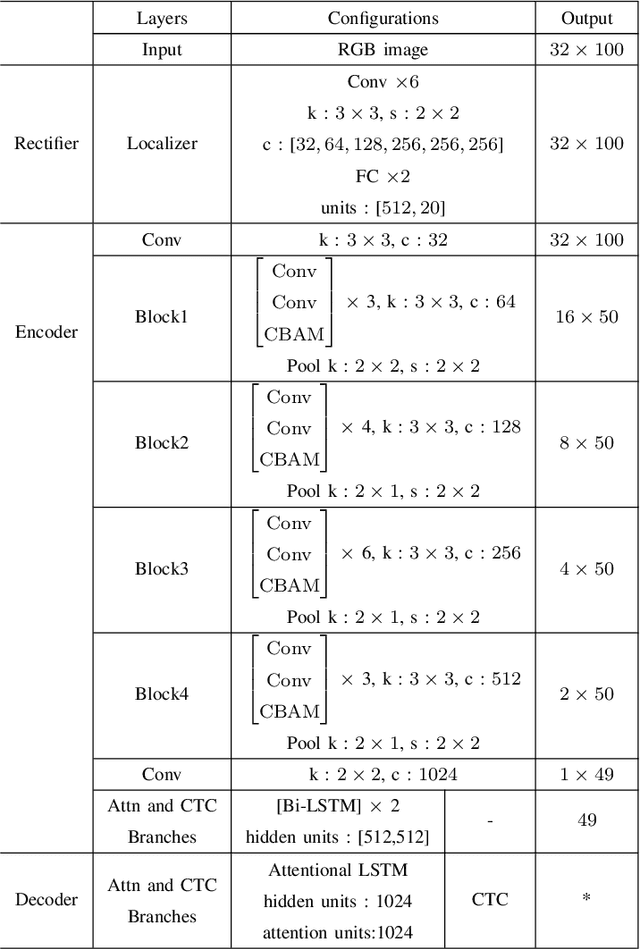
In recent years, scene text recognition is always regarded as a sequence-to-sequence problem. Connectionist Temporal Classification (CTC) and Attentional sequence recognition (Attn) are two very prevailing approaches to tackle this problem while they may fail in some scenarios respectively. CTC concentrates more on every individual character but is weak in text semantic dependency modeling. Attn based methods have better context semantic modeling ability while tends to overfit on limited training data. In this paper, we elaborately design a Rectified Attentional Double Supervised Network (ReADS) for general scene text recognition. To overcome the weakness of CTC and Attn, both of them are applied in our method but with different modules in two supervised branches which can make a complementary to each other. Moreover, effective spatial and channel attention mechanisms are introduced to eliminate background noise and extract valid foreground information. Finally, a simple rectified network is implemented to rectify irregular text. The ReADS can be trained end-to-end and only word-level annotations are required. Extensive experiments on various benchmarks verify the effectiveness of ReADS which achieves state-of-the-art performance.