 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRe-purposing Compact Neuronal Circuit Policies to Govern Reinforcement Learning Tasks
Paper and Code
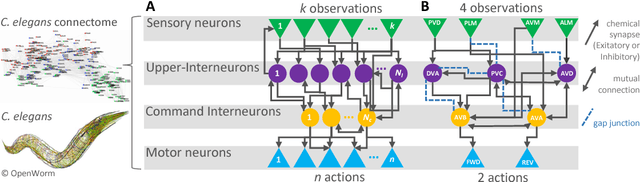


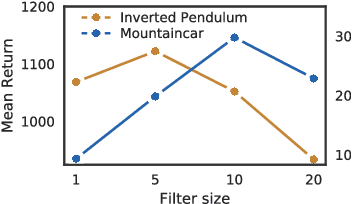
We propose an effective method for creating interpretable control agents, by \textit{re-purposing} the function of a biological neural circuit model, to govern simulated and real world reinforcement learning (RL) test-beds. Inspired by the structure of the nervous system of the soil-worm, \emph{C. elegans}, we introduce \emph{Neuronal Circuit Policies} (NCPs) as a novel recurrent neural network instance with liquid time-constants, universal approximation capabilities and interpretable dynamics. We theoretically show that they can approximate any finite simulation time of a given continuous n-dimensional dynamical system, with $n$ output units and some hidden units. We model instances of the policies and learn their synaptic and neuronal parameters to control standard RL tasks and demonstrate its application for autonomous parking of a real rover robot on a pre-defined trajectory. For reconfiguration of the \emph{purpose} of the neural circuit, we adopt a search-based RL algorithm. We show that our neuronal circuit policies perform as good as deep neural network policies with the advantage of realizing interpretable dynamics at the cell-level. We theoretically find bounds for the time-varying dynamics of the circuits, and introduce a novel way to reason about networks' dynamics.