 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRangeAugment: Efficient Online Augmentation with Range Learning
Paper and Code
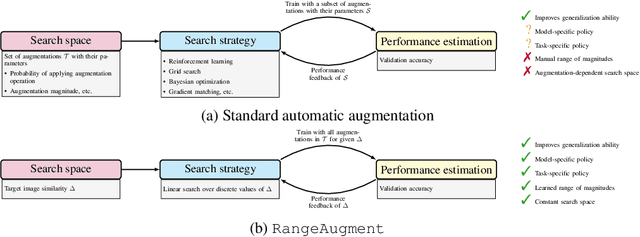


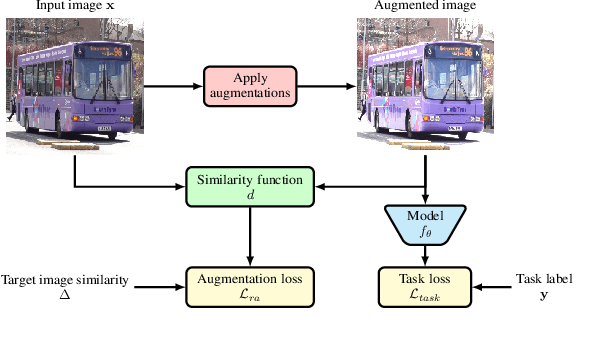
State-of-the-art automatic augmentation methods (e.g., AutoAugment and RandAugment) for visual recognition tasks diversify training data using a large set of augmentation operations. The range of magnitudes of many augmentation operations (e.g., brightness and contrast) is continuous. Therefore, to make search computationally tractable, these methods use fixed and manually-defined magnitude ranges for each operation, which may lead to sub-optimal policies. To answer the open question on the importance of magnitude ranges for each augmentation operation, we introduce RangeAugment that allows us to efficiently learn the range of magnitudes for individual as well as composite augmentation operations. RangeAugment uses an auxiliary loss based on image similarity as a measure to control the range of magnitudes of augmentation operations. As a result, RangeAugment has a single scalar parameter for search, image similarity, which we simply optimize via linear search. RangeAugment integrates seamlessly with any model and learns model- and task-specific augmentation policies. With extensive experiments on the ImageNet dataset across different networks, we show that RangeAugment achieves competitive performance to state-of-the-art automatic augmentation methods with 4-5 times fewer augmentation operations. Experimental results on semantic segmentation, object detection, foundation models, and knowledge distillation further shows RangeAugment's effectiveness.