 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQualitative Measurements of Policy Discrepancy for Return-based Deep Q-Network
Paper and Code
Jul 08, 2018
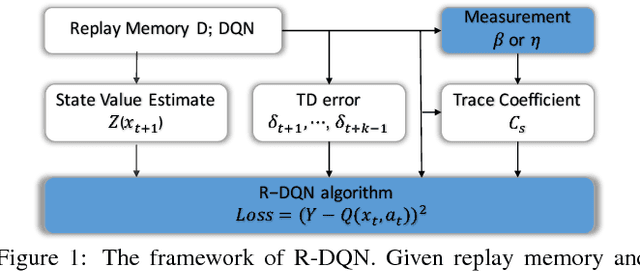
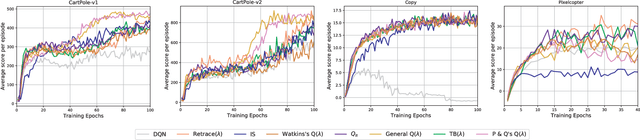
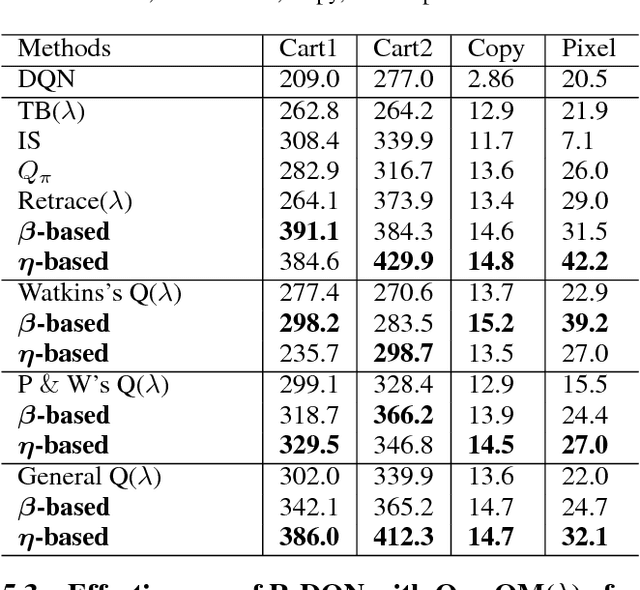
The deep Q-network (DQN) and return-based reinforcement learning are two promising algorithms proposed in recent years. DQN brings advances to complex sequential decision problems, while return-based algorithms have advantages in making use of sample trajectories. In this paper, we propose a general framework to combine DQN and most of the return-based reinforcement learning algorithms, named R-DQN. We show the performance of traditional DQN can be improved effectively by introducing return-based reinforcement learning. In order to further improve the R-DQN, we design a strategy with two measurements which can qualitatively measure the policy discrepancy. Moreover, we give the two measurements' bounds in the proposed R-DQN framework. We show that algorithms with our strategy can accurately express the trace coefficient and achieve a better approximation to return. The experiments, conducted on several representative tasks from the OpenAI Gym library, validate the effectiveness of the proposed measurements. The results also show that the algorithms with our strategy outperform the state-of-the-art methods.