 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePV-RCNN++: Semantical Point-Voxel Feature Interaction for 3D Object Detection
Paper and Code
Aug 29, 2022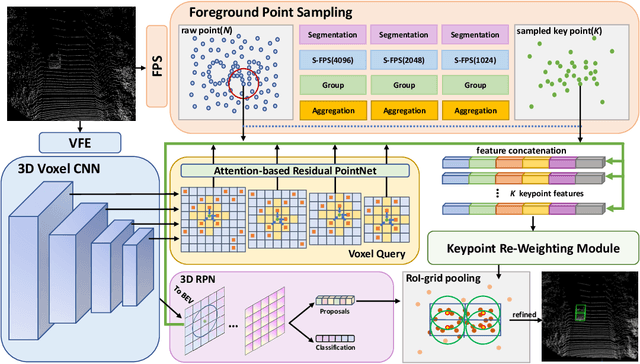
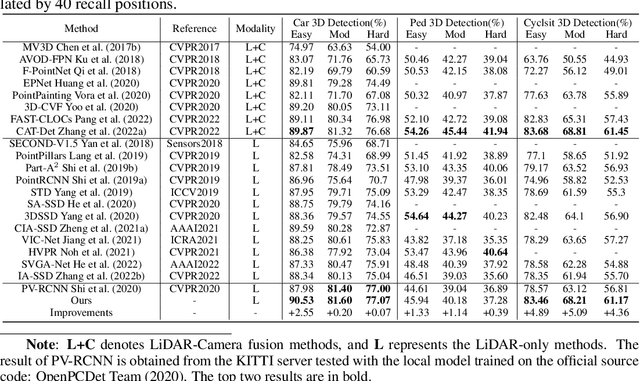
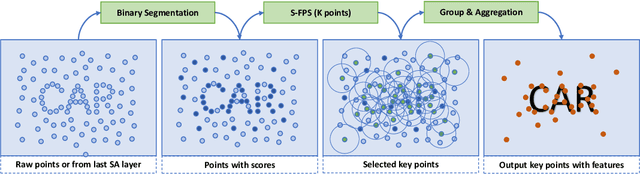
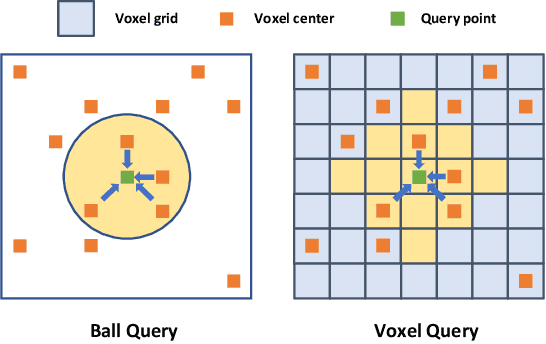
Large imbalance often exists between the foreground points (i.e., objects) and the background points in outdoor LiDAR point clouds. It hinders cutting-edge detectors from focusing on informative areas to produce accurate 3D object detection results. This paper proposes a novel object detection network by semantical point-voxel feature interaction, dubbed PV-RCNN++. Unlike most of existing methods, PV-RCNN++ explores the semantic information to enhance the quality of object detection. First, a semantic segmentation module is proposed to retain more discriminative foreground keypoints. Such a module will guide our PV-RCNN++ to integrate more object-related point-wise and voxel-wise features in the pivotal areas. Then, to make points and voxels interact efficiently, we utilize voxel query based on Manhattan distance to quickly sample voxel-wise features around keypoints. Such the voxel query will reduce the time complexity from O(N) to O(K), compared to the ball query. Further, to avoid being stuck in learning only local features, an attention-based residual PointNet module is designed to expand the receptive field to adaptively aggregate the neighboring voxel-wise features into keypoints. Extensive experiments on the KITTI dataset show that PV-RCNN++ achieves 81.60$\%$, 40.18$\%$, 68.21$\%$ 3D mAP on Car, Pedestrian, and Cyclist, achieving comparable or even better performance to the state-of-the-arts.