 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePTDE: Personalized Training with Distillated Execution for Multi-Agent Reinforcement Learning
Paper and Code
Oct 17, 2022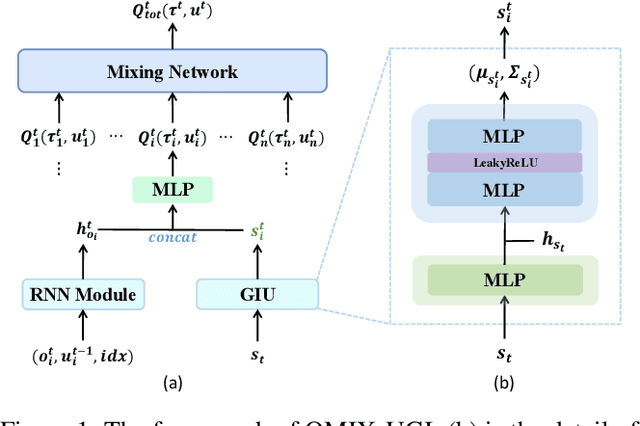
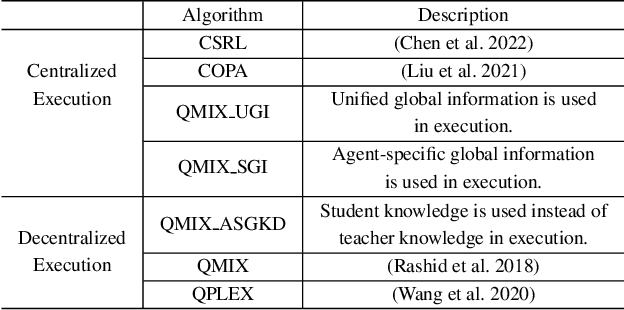
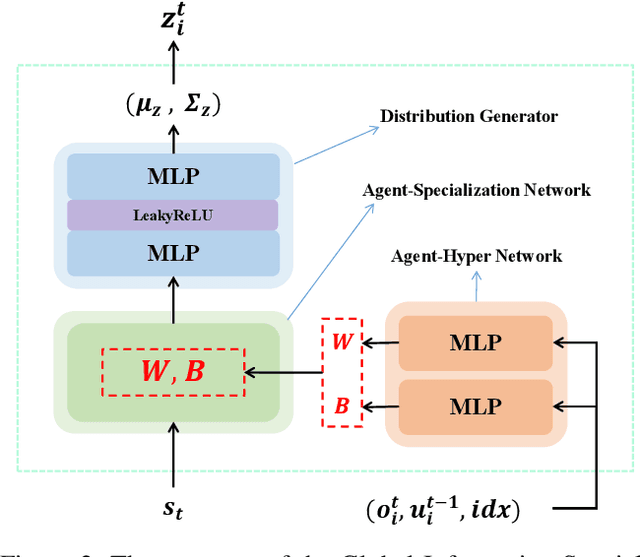
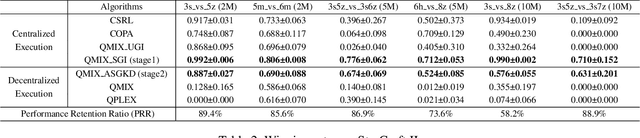
Centralized Training with Decentralized Execution (CTDE) has been a very popular paradigm for multi-agent reinforcement learning. One of its main features is making full use of the global information to learn a better joint $Q$-function or centralized critic. In this paper, we in turn explore how to leverage the global information to directly learn a better individual $Q$-function or individual actor. We find that applying the same global information to all agents indiscriminately is not enough for good performance, and thus propose to specify the global information for each agent to obtain agent-specific global information for better performance. Furthermore, we distill such agent-specific global information into the agent's local information, which is used during decentralized execution without too much performance degradation. We call this new paradigm Personalized Training with Distillated Execution (PTDE). PTDE can be easily combined with many state-of-the-art algorithms to further improve their performance, which is verified in both SMAC and Google Research Football scenarios.