 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvably Efficient Reinforcement Learning for Online Adaptive Influence Maximization
Paper and Code
Jun 29, 2022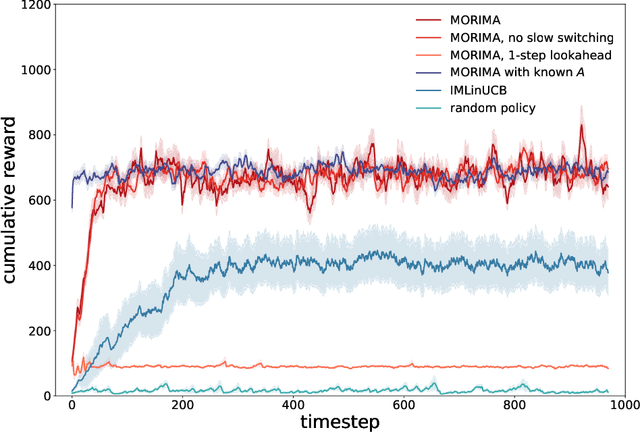
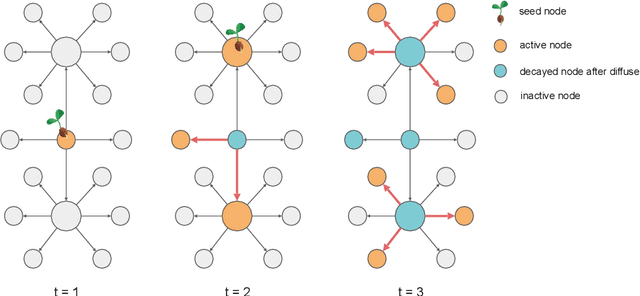
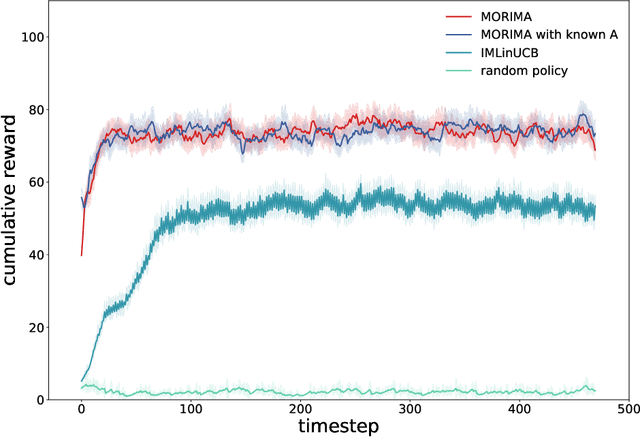
Online influence maximization aims to maximize the influence spread of a content in a social network with unknown network model by selecting a few seed nodes. Recent studies followed a non-adaptive setting, where the seed nodes are selected before the start of the diffusion process and network parameters are updated when the diffusion stops. We consider an adaptive version of content-dependent online influence maximization problem where the seed nodes are sequentially activated based on real-time feedback. In this paper, we formulate the problem as an infinite-horizon discounted MDP under a linear diffusion process and present a model-based reinforcement learning solution. Our algorithm maintains a network model estimate and selects seed users adaptively, exploring the social network while improving the optimal policy optimistically. We establish $\widetilde O(\sqrt{T})$ regret bound for our algorithm. Empirical evaluations on synthetic network demonstrate the efficiency of our algorithm.