 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvable Adaptivity in Adam
Paper and Code
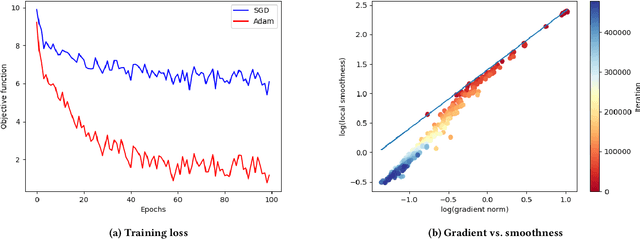


Adaptive Moment Estimation (Adam) optimizer is widely used in deep learning tasks because of its fast convergence properties. However, the convergence of Adam is still not well understood. In particular, the existing analysis of Adam cannot clearly demonstrate the advantage of Adam over SGD. We attribute this theoretical embarrassment to $L$-smooth condition (i.e., assuming the gradient is globally Lipschitz continuous with constant $L$) adopted by literature, which has been pointed out to often fail in practical neural networks. To tackle this embarrassment, we analyze the convergence of Adam under a relaxed condition called $(L_0,L_1)$ smoothness condition, which allows the gradient Lipschitz constant to change with the local gradient norm. $(L_0,L_1)$ is strictly weaker than $L$-smooth condition and it has been empirically verified to hold for practical deep neural networks. Under the $(L_0,L_1)$ smoothness condition, we establish the convergence for Adam with practical hyperparameters. Specifically, we argue that Adam can adapt to the local smoothness condition, justifying the \emph{adaptivity} of Adam. In contrast, SGD can be arbitrarily slow under this condition. Our result might shed light on the benefit of adaptive gradient methods over non-adaptive ones.