 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePre-trained Language Models in Biomedical Domain: A Systematic Survey
Paper and Code


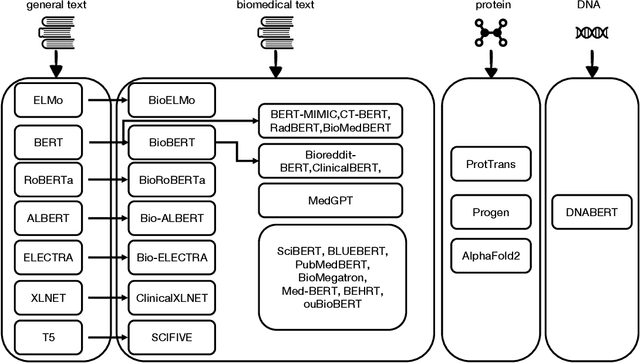

Pre-trained language models (PLMs) have been the de facto paradigm for most natural language processing (NLP) tasks. This also benefits biomedical domain: researchers from informatics, medicine, and computer science (CS) communities propose various PLMs trained on biomedical datasets, e.g., biomedical text, electronic health records, protein, and DNA sequences for various biomedical tasks. However, the cross-discipline characteristics of biomedical PLMs hinder their spreading among communities; some existing works are isolated from each other without comprehensive comparison and discussions. It expects a survey that not only systematically reviews recent advances of biomedical PLMs and their applications but also standardizes terminology and benchmarks. In this paper, we summarize the recent progress of pre-trained language models in the biomedical domain and their applications in biomedical downstream tasks. Particularly, we discuss the motivations and propose a taxonomy of existing biomedical PLMs. Their applications in biomedical downstream tasks are exhaustively discussed. At last, we illustrate various limitations and future trends, which we hope can provide inspiration for the future research of the research community.