 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosterior Consistency of Semi-Supervised Regression on Graphs
Paper and Code
Jul 25, 2020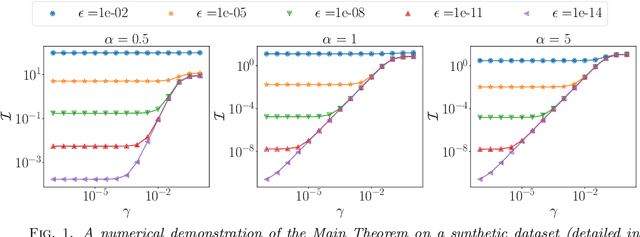

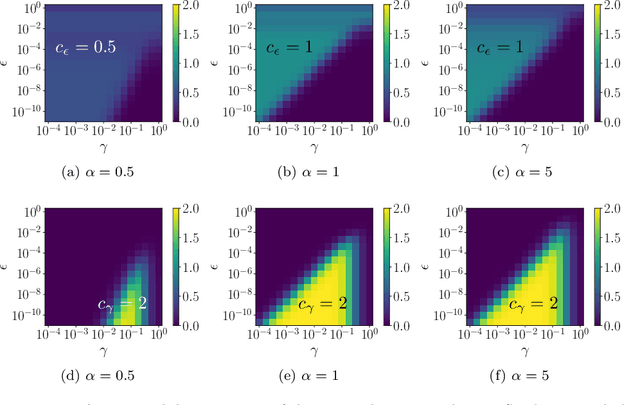

Graph-based semi-supervised regression (SSR) is the problem of estimating the value of a function on a weighted graph from its values (labels) on a small subset of the vertices. This paper is concerned with the consistency of SSR in the context of classification, in the setting where the labels have small noise and the underlying graph weighting is consistent with well-clustered nodes. We present a Bayesian formulation of SSR in which the weighted graph defines a Gaussian prior, using a graph Laplacian, and the labeled data defines a likelihood. We analyze the rate of contraction of the posterior measure around the ground truth in terms of parameters that quantify the small label error and inherent clustering in the graph. We obtain bounds on the rates of contraction and illustrate their sharpness through numerical experiments. The analysis also gives insight into the choice of hyperparameters that enter the definition of the prior.