 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoseTriplet: Co-evolving 3D Human Pose Estimation, Imitation, and Hallucination under Self-supervision
Paper and Code
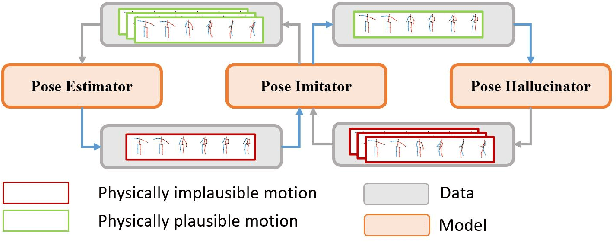

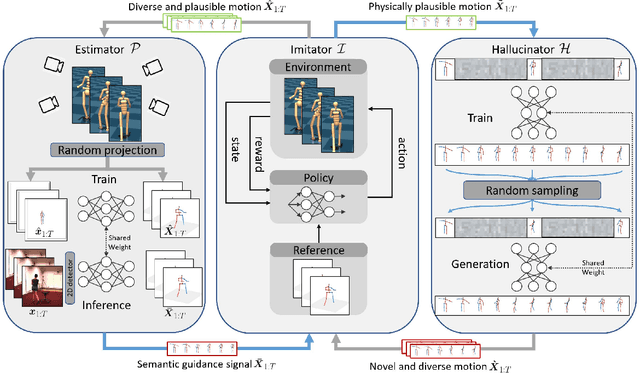
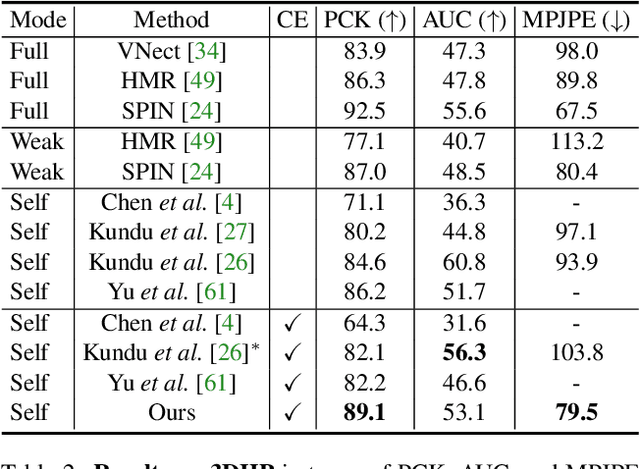
Existing self-supervised 3D human pose estimation schemes have largely relied on weak supervisions like consistency loss to guide the learning, which, inevitably, leads to inferior results in real-world scenarios with unseen poses. In this paper, we propose a novel self-supervised approach that allows us to explicitly generate 2D-3D pose pairs for augmenting supervision, through a self-enhancing dual-loop learning framework. This is made possible via introducing a reinforcement-learning-based imitator, which is learned jointly with a pose estimator alongside a pose hallucinator; the three components form two loops during the training process, complementing and strengthening one another. Specifically, the pose estimator transforms an input 2D pose sequence to a low-fidelity 3D output, which is then enhanced by the imitator that enforces physical constraints. The refined 3D poses are subsequently fed to the hallucinator for producing even more diverse data, which are, in turn, strengthened by the imitator and further utilized to train the pose estimator. Such a co-evolution scheme, in practice, enables training a pose estimator on self-generated motion data without relying on any given 3D data. Extensive experiments across various benchmarks demonstrate that our approach yields encouraging results significantly outperforming the state of the art and, in some cases, even on par with results of fully-supervised methods. Notably, it achieves 89.1% 3D PCK on MPI-INF-3DHP under self-supervised cross-dataset evaluation setup, improving upon the previous best self-supervised methods by 8.6%. Code can be found at: https://github.com/Garfield-kh/PoseTriplet