 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolymatrix Competitive Gradient Descent
Paper and Code
Nov 16, 2021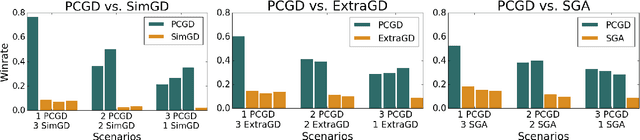
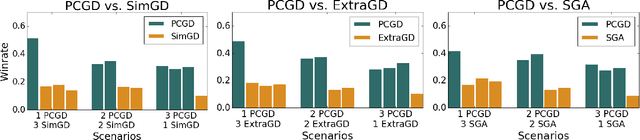


Many economic games and machine learning approaches can be cast as competitive optimization problems where multiple agents are minimizing their respective objective function, which depends on all agents' actions. While gradient descent is a reliable basic workhorse for single-agent optimization, it often leads to oscillation in competitive optimization. In this work we propose polymatrix competitive gradient descent (PCGD) as a method for solving general sum competitive optimization involving arbitrary numbers of agents. The updates of our method are obtained as the Nash equilibria of a local polymatrix approximation with a quadratic regularization, and can be computed efficiently by solving a linear system of equations. We prove local convergence of PCGD to stable fixed points for $n$-player general-sum games, and show that it does not require adapting the step size to the strength of the player-interactions. We use PCGD to optimize policies in multi-agent reinforcement learning and demonstrate its advantages in Snake, Markov soccer and an electricity market game. Agents trained by PCGD outperform agents trained with simultaneous gradient descent, symplectic gradient adjustment, and extragradient in Snake and Markov soccer games and on the electricity market game, PCGD trains faster than both simultaneous gradient descent and the extragradient method.