 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolyak-Ruppert Averaged Q-Leaning is Statistically Efficient
Paper and Code
Jan 23, 2022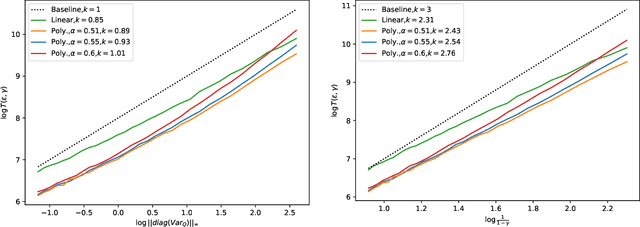
We study synchronous Q-learning with Polyak-Ruppert averaging (a.k.a., averaged Q-learning) in a $\gamma$-discounted MDP. We establish a functional central limit theorem (FCLT) for the averaged iteration $\bar{\boldsymbol{Q}}_T$ and show its standardized partial-sum process weakly converges to a rescaled Brownian motion. Furthermore, we show that $\bar{\boldsymbol{Q}}_T$ is actually a regular asymptotically linear (RAL) estimator for the optimal Q-value function $\boldsymbol{Q}^*$ with the most efficient influence function. This implies the averaged Q-learning iteration has the smallest asymptotic variance among all RAL estimators. In addition, we present a non-asymptotic analysis for the $\ell_{\infty}$ error $\mathbb{E}\|\bar{\boldsymbol{Q}}_T-\boldsymbol{Q}^*\|_{\infty}$, showing for polynomial step sizes it matches the instance-dependent lower bound as well as the optimal minimax complexity lower bound. In short, our theoretical analysis shows averaged Q-learning is statistically efficient.