 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoint-Level Temporal Action Localization: Bridging Fully-supervised Proposals to Weakly-supervised Losses
Paper and Code
Dec 15, 2020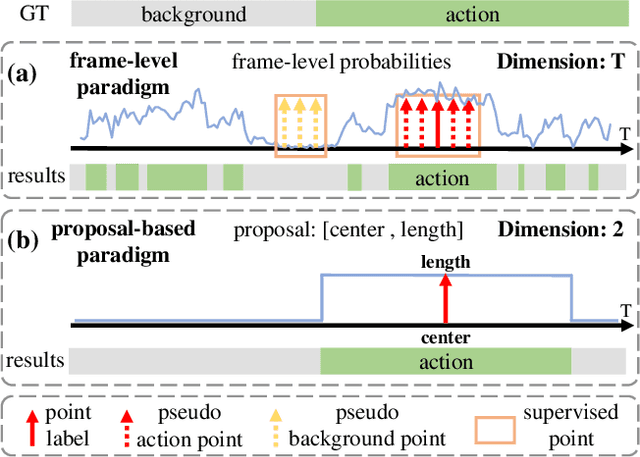



Point-Level temporal action localization (PTAL) aims to localize actions in untrimmed videos with only one timestamp annotation for each action instance. Existing methods adopt the frame-level prediction paradigm to learn from the sparse single-frame labels. However, such a framework inevitably suffers from a large solution space. This paper attempts to explore the proposal-based prediction paradigm for point-level annotations, which has the advantage of more constrained solution space and consistent predictions among neighboring frames. The point-level annotations are first used as the keypoint supervision to train a keypoint detector. At the location prediction stage, a simple but effective mapper module, which enables back-propagation of training errors, is then introduced to bridge the fully-supervised framework with weak supervision. To our best of knowledge, this is the first work to leverage the fully-supervised paradigm for the point-level setting. Experiments on THUMOS14, BEOID, and GTEA verify the effectiveness of our proposed method both quantitatively and qualitatively, and demonstrate that our method outperforms state-of-the-art methods.