 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePMLB: A Large Benchmark Suite for Machine Learning Evaluation and Comparison
Paper and Code
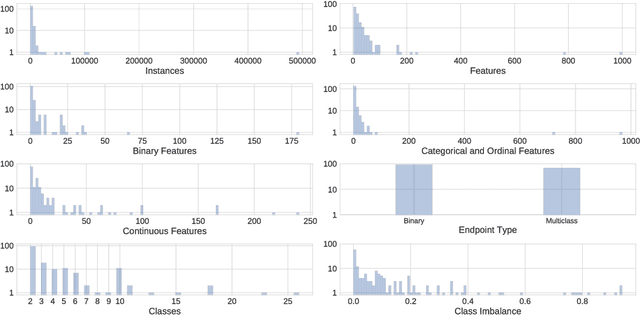
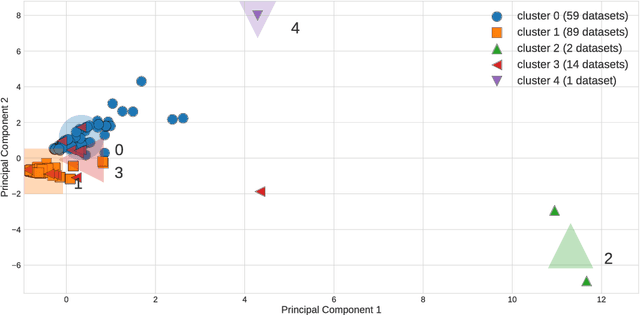
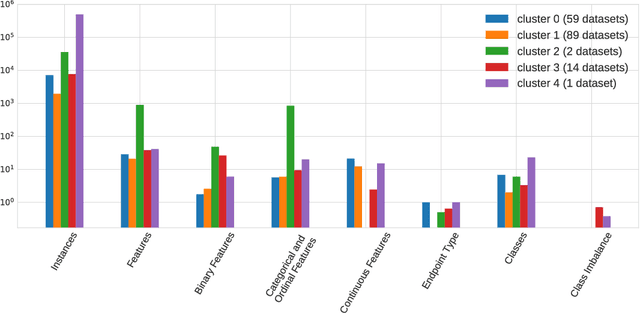
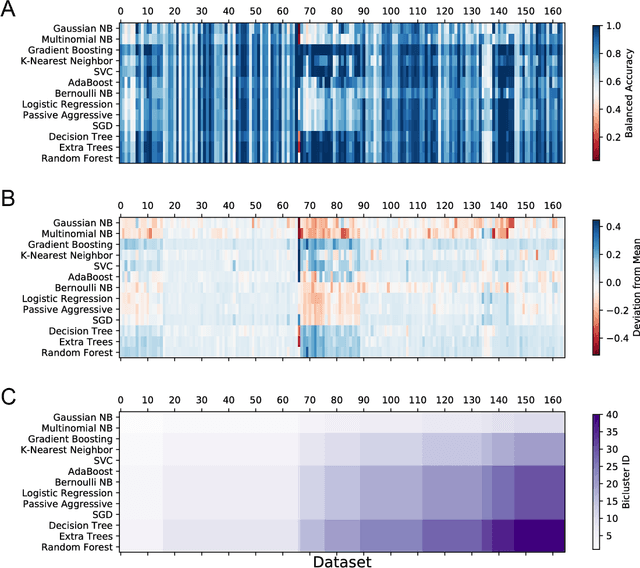
The selection, development, or comparison of machine learning methods in data mining can be a difficult task based on the target problem and goals of a particular study. Numerous publicly available real-world and simulated benchmark datasets have emerged from different sources, but their organization and adoption as standards have been inconsistent. As such, selecting and curating specific benchmarks remains an unnecessary burden on machine learning practitioners and data scientists. The present study introduces an accessible, curated, and developing public benchmark resource to facilitate identification of the strengths and weaknesses of different machine learning methodologies. We compare meta-features among the current set of benchmark datasets in this resource to characterize the diversity of available data. Finally, we apply a number of established machine learning methods to the entire benchmark suite and analyze how datasets and algorithms cluster in terms of performance. This work is an important first step towards understanding the limitations of popular benchmarking suites and developing a resource that connects existing benchmarking standards to more diverse and efficient standards in the future.