Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlasticity-Enhanced Domain-Wall MTJ Neural Networks for Energy-Efficient Online Learning
Paper and Code
Mar 04, 2020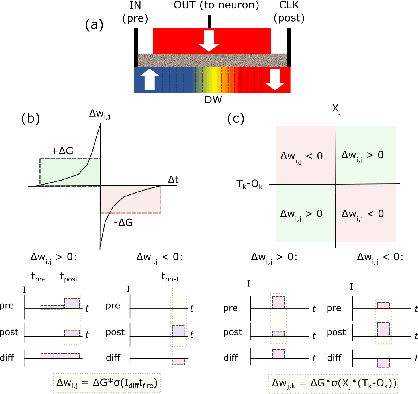
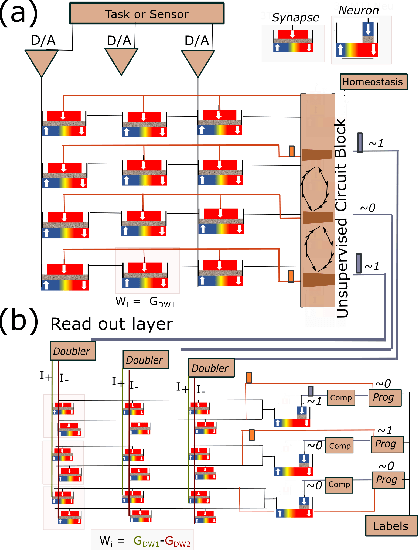
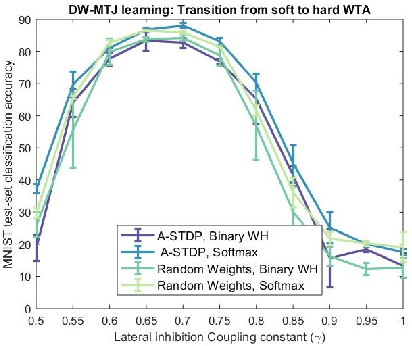
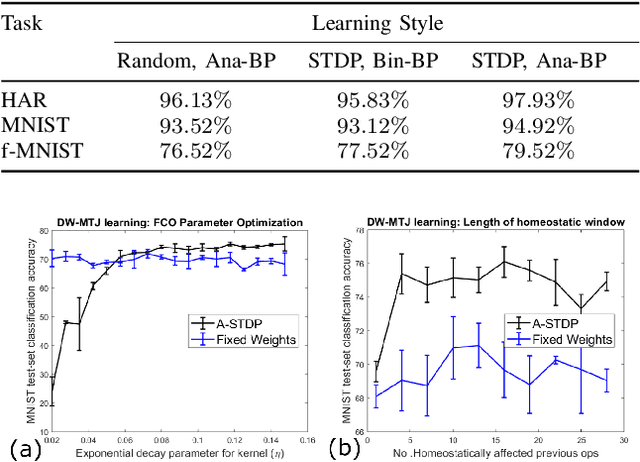
Machine learning implements backpropagation via abundant training samples. We demonstrate a multi-stage learning system realized by a promising non-volatile memory device, the domain-wall magnetic tunnel junction (DW-MTJ). The system consists of unsupervised (clustering) as well as supervised sub-systems, and generalizes quickly (with few samples). We demonstrate interactions between physical properties of this device and optimal implementation of neuroscience-inspired plasticity learning rules, and highlight performance on a suite of tasks. Our energy analysis confirms the value of the approach, as the learning budget stays below 20 $\mu J$ even for large tasks used typically in machine learning.
View paper on